工业互联网安全 | 考试要点
一、判断题
1. 勒索攻击,以Unity系列PLC为例
P81
施耐德 Unity 系列 PLC 与 UnityOS 管理层内核级协议 UMAS(Ultrant Media Access Service)基于 Modbus 协议,用于 PLC、SCADA 系统访问内存,该协议会话密钥存在“躲避身份验证”漏洞,使 PLC 易受关键资产和基础设施勒索攻击。攻击者还能够操纵 PLC 发出的射频信号,并不依赖 PLC 的任何漏洞或设计缺陷。
当数据写入 PLC 内存时,其频率会发生改变。通过操纵该频率,攻击者可实现数据的逐位窃取,0 表示某个特定频率,而其他频率则用“1”表示。通过附近天线来获取该频率信号,并通过软件定义无线电(Software-Defined Radio,SDR)来实现解码。攻击者将恶意梯形图上传至 PLC,并以特定周期写入 PLC 内存,调制射频信号频率,实现敏感数据窃取,包括工控网络拓扑结构、通信协议及设备、人机接口信息等。
2. Modbus TCP协议数据包封装与端口
P112
Modbus/TCP 协议则是在 TCP 应用层将 Modbus 协议修改并封装进去,传输层、网络层、数据链路层及物理层仍基于 TCP 协议(端口 502)。接收端收到 Modbus/TCP 协议数据包后,拆封出原始 Modbus 帧并解析,返回给发送端的数据包则仍是通过 TCP 协议重新封装发送。
3. SCADA系统构成及安全性
P55
SCADA 用于工业现场的工业数据采集与监控,包括 RTU、PLC、通信基础设施、HMI、监控计算机等,用于完成工业数据采集、现场设备控制、参数测量与控制、现场报警、人机交互等目的。RTU、PLC、PAC 或 DCS 等均可以作为 SCADA的核心控制器,具体因控制现场工况需求而异。
典型的 SCADA 包括控制中心与远程现场站点等。根据规模,控制中心可分为主控制中心、区域控制中心、冗余制中心。各中心与全部远程现场站点通过 IP 网、卫星、微波、有线等远程通信实现点对点连接,而各中心又通过广域网相互连接,并可供工业互联网或者企业访问。SCADA 还能够实现现场站点的故障诊断、修复和系统维护。
SCADA 的通信对象可以是内部子系统、输入/输出设备以及外部系统等。Client/Server 间、Server/Server 间通信多采取请求、订阅和广播形式。SCADA与外界多采用 OPC Client 与 OPC Server 实现通信。当前,SCADA 已逐渐向开放式通用 IP 网络转变。
4. 工业物联网带来的网络脆弱性挑战
P94
工业物联网的主流通信协议是 TCP/IP,因此,工业物联网不仅面临着传统 IP网络的安全风险,还面临着工业物联网具有“工业特征”的特有安全问题。比如,工业物联网感知层所采集的工业数据,来源众多,格式与结构各异,安全问题复杂性更强。该层所采用的 RFID、无线传感器等信息获取机制,所涉及的硬件产品及驻留软件均带有大量脆弱性问题。
此外,工业物联网采用的各种通信与控制协议,比如 Ethernet、CAN、Profibus、RS485/422 以及 FF 等,也是漏洞频报。有些脆弱性危害巨大,比如心脏出血(Heartbleed)漏洞几乎可威胁所有的工业网络硬件,包括工业路由器、交换机以及各类工业“物联”现场装置。
SCADA、DCS、PLC 等系统也具有很多特殊脆弱性,可采用工业安全准入评测系统(Security Testing sYstem for protocol X,STYX)之类的工具进行评测。
5. 工业互联网网络传输安全问题
P124
采用Modbus/TCP协议:
特点及安全风险:
无身份认证机制,明文传输,无完整性与机密性保护,兼具 TCP/IP 及 Modbus 双重风险。可基于 Modbus 设备修改控制器 I/O或寄存器数值、复位、禁用,或安装新版逻辑或固件。
安全风险规避手段:
协议深度检测及防护,可定义 Modbus 指令、寄存器及线圈列表,阻止不合规流量,防范功能码滥用;认证通信客户端与服务端身份及设备状态,保证设备不可仿冒、操作系统和组态软件可信;采用 HMAC 等算法保证数据完整性;对 Modbus 控制指令进行安全分级,对关键功能码指令采取加密相传输,保证机密性。
6. 工业大数据应用内涵
P180
工业大数据应用的关键是结合不同的工业应用场景,对各种工业数据的内在关联进行揭示和表达。工业大数据与工业互联网相伴相生,在整个工业生产的需求分析、设计研发、生产制造和销售服务等全流程当中都起到非常重要的作用。因此,应用工业大数据既要掌握工业大数据自身的知识和工具,更要了解典型的工业业务场景,安全问题的解决方案更应结合业务场景来制定和决策。
7. 工业防火墙渗透的手段:静态和动态。
P118:突破工业防火墙的攻击风险防范问题
分片攻击
IP地址欺骗攻击
协议隧道攻击
攻击者可以将一种协议封装在另一种协议当中,即将其他工业协议的数据内容通过封装后利用隧道发送。比如,将某些恶意数据隐藏在应用层协议分组头部,再封装为传输层协议,由于工业防火墙无法判断进出的报文内容是否合法,恶意数据就避开了工业防火墙 ACL 检测。许多工业防火墙对 ICMP 与 UDP 报文并未限制,因此恶意数据即可混迹于正常报文中突破防火墙。以 HTTP 协议隧道攻击为例,攻击者可利用 HTTP 请求建立双向虚拟连接,并在防火墙防护区内外分别部署客户端与服务端程序,将恶意数据封装在正常 HTTP 请求之内,便可实现防火墙渗透。
木马攻击
采用木马攻击进行工业防火墙渗透的手段有两种,一种是针对静态包过滤型工业防火墙的普通木马攻击,另一种是针对动态包过滤型防火墙的反弹端口型木马攻击,二者均采用“C/S”架构来实现远程控制。
静态
渗透静态包过滤型工业防火墙,多是利用被保护网络中开放的服务漏洞,通过 UNICODE 编码、Web Shell 提权等攻击手段,将木马程序上传,并运行其客户端程 序。由于 1024 以上高端口专为特殊服务所用,因此普通工业防火墙仅过滤 1024 以 下的低端口,如果木马客户端利用高端口来建立监听,便可与外部服务端实时通信 而不会遭到工业防火墙过滤。这类木马攻击可以利用 DPI 技术强化 IP 包过滤规则来 阻断,亦可通过监听非法连接来识别。
动态
不过,工业防火墙对于从受信任内网向外网发出的连接请求大多监管不严,可被反弹端口型木马利用,其被控制端(服务端)会主动监测控制端(客户端),发现其在线即弹出常用的正常端口,伪装成合法请求以建立对外端口连接,即“反弹端口”。防范反弹端口型木马,一是关闭不用的端口,比如:TCP 139、445、593、1025 端口;UDP123、137、138、445、1900 端口;TCP 2513、2745、3127、6129 等常见后门端口;3389 等远程服务访问端口。其中,137、138、139、445 端口为 NetBios协议应用共享端口。二是使用杀毒软件或反木马软件来清除木马程序。三是使用TCPView 等工具来监测非法连接情况。
8. 基于主机和基于网络的入侵检测技术的区别
工业互联网检测技术(上)P5
基于主机的入侵检测:系统部署在被检测的主机系统上,通过监视分析从主机上获取的审计记录、日志文件、系统调用、文件修改或其他主机状态和活动等对攻击行为进行检测。
基于网络的入侵检测技术:研究对象是网络流量,该技术分析流量模式或对传输的网络数据包进行深度包解析,提取流量特征或根据协议格式解析数据包中详细字段特征信息,实时检测来自网络的异常攻击行为。
9. 工业微服务的用户与服务认证
P165
无论安全需求、架构如何逐步演进,用户身份认证与鉴权仍是微服务安全的基本保证手段之一。采用工业微服务架构的工业互联网平台中,每个面向用户的工业服务均需要与认证服务交互,易生成大量的琐碎网络流量,同时认证工作重复性严重,如多个微应用组合成工业应用时,认证难度进一步加大。工业微服务集与外部的交互通常是采用 API 网关模式来实现,需要声明的微服务可在该网关处获取相应的 API。需要指出,并非全部微服务均必须通过 API 网关来实现声明。微服务用户通过 API 实现对微服务的访问,应在 API 网关处进行身份认证。
工业微服务用户身份认证可使用以下方法:数字证书;客户端 ID 和口令;开放授权(Open Authorization,OAuth)、Open ID Connect 或安全声明标记语言(SecurityAssertion Markup Language,SAML)等行业标准协议。如安全性要求较高,可采用多因素认证。
通过身份认证的客户端,其操作还需要明确授权。针对微服务架构各层均需根据最小特权原则分别授权。授权对象可以是客户端证书或者客户端 ID,授权可存于数据库、缓存层或共享文件系统。
工业微服务 API 认证,不仅需要认证最终用户身份,也需要认证应用和服务的身份,即微服务调用间的 API 安全与信任问题。采用 IP 网段或专用网络隔离保护拆分服务、配置 Kerberos 等认证系统的方式,虽然简单易行、迁移上线速度快,但其缺点也非常明显,比如对底层网络架构依赖严重、易错误配置、不宜向外网暴露等。
采用工业微服务架构,一个工业 APP 应用可被拆分成多个工业微应用,而每个工业微应用 API 均需对服务请求进行认证,以确认当前请求的合法性及其相应访问请求的权限。此时,需要关注外部工业应用接入、用户-微服务 API 的认证、微服务API 之间的认证等多种场景,以保证 API 具有强安全级别的认证模式,而且全部令牌、密钥及凭据均得到有效保护。
10. 位操作与输出操作指令,标准“输出”
工业互联网编程技术,P7
11. 比较和移位操作指令
工业互联网编程技术,P32
“标准输出”和“立即输出”:* 和 *I
分别为标准输出和立即输出指令。bit
为要操作的触点,指令执行时对该触点的对应位值进行操作。
标准“输出”操作指令表示将电路中输出线圈前的运算结果写入寄存器,并根据寄存器的写入结果控制对应的触点。
立即“输出”操作指令则表示将电路中输出线圈前的运算结果写入寄存器,并直接驱动实际输出。因此,立即“输出”不受 PLC 扫描周期的限制,程序执行到该指令时直接驱动实际输出。
12. 梯形图和功能块图都可以转化为指令表程序
13. 工业互联网安全风险涉及的要素分析,风险公式定义
P34
工业互联网的风险是指导致损失或伤害的情形,风险度量则依赖于安全事件发生频率及其损害的严重程度。在工业互联网的构建全生命周期中,均以进行风险评估,并采取有效措施来减缓安全事件的影响及危害,因此,必须对工业互联网的风险因素进行识别、分析、度量、评估与管理。
工业互联网风险的形成,同工业互联网的构成要素密切相关,即与系统拥有的资产、具有的脆弱性以及面临的威胁有关。资产要素的识别主要是依靠它对系统的价值贡献大小来衡量。同时,资产在不同时刻所处的状态也不一致。比如,网络连接可以处于正常、不稳定、崩溃等多种状态。网络中风险的含义是 R*A×T×V×C,其中,R 为风险,A 为资产价值,V 为脆弱性,C 是后果或者破坏程度。风险控制的目标,就是通过特定的算法,将目标强化资源配置到节点和链路上,通过优先保护高价值节点来实现整体风险控制的优化。网络包含众多组件或资产,网络的威胁、脆弱性、后果和风险将是其组件或资产的威胁、脆弱性、后果和风险的总和。网络中的组件根据性质不同,可以分别抽象为节点或者链路,因此,网络风险就可以定义为所有节点和链路的风险总和。
风险与安全密切相关,从某种意义上说,风险就是可接受的安全程度。在进行工业互联网安全风险分析时,应从技术、管理(包括运维)等方面来讨论。
14. 工业防火墙探测攻击风险防范问题
P117
通过互联网进行工业设备扫描,可扫描出工业互联网上的各种网络设备、主机、服务器、工业控制设备、安全设备甚至是工业现场控制设备。Firewalk 和 NMAP 等工具可直接用于工业防火墙信息探测。这些工具既可以探测防火墙所保护网络的拓扑结构,也可以分析防火墙的功能。
Firewalk 的技术核心是利用路由跟踪分析技术来分析 IP 报文并测定防火墙ACL。该方法工作于 IP 层,可通过 TCP、UDP 和 ICMP 等协议来利用 IP 上层的所有协议。比如,路由跟踪器向工业防火墙后的目标主机发送 UDP、TCP 或 ICMP echo的特殊数据包,并观察能否从攻击源主机传输至工业防火墙之后的目标主机,由此探测防火墙 ACL 中打开或允许通过的端口。此外,还可以探测出包含各种控制信息的报文能否通过工业防火墙。
15. PROFINET数据包易遭受攻击的种类
工业互联网通信协议与安全P3
PROFINET数据包重放攻击:
PROFINET协议的开放性使得该标准容易受到诸如包嗅探、包重放和操纵等攻击;
通过捕获PROFINET/DCP发现包,在Scapy中导入,进行操作、重放,可获取攻击结果。
二、选择题
1. 防火墙绕过手段
ppt第二章《工业互联网安全体系》32页,
网内信息搜针对工业互联网的入侵与攻击-集:
典型手段:通常采用网络搜索、域名管理/搜索服务、网络扫描、社会工程等手段,以尽可能详细地了解被攻击系统拓扑结构、软硬件配置、用户信息、安全措施等重要信息。
重要突破:两个工业防火墙:一个位于业务局域网与互联网之间,另一个位于内部局域网与业务局域网之间。
防火墙绕过手段:具体方法有IP地址欺骗、分片攻击、木马攻击和协议隧道攻击等。突破后,需找到该内部局域网控制的下层智能设备、传感器等实施细节,尤其是控制系统局域网中最重要的数据采集服务器数据库和HMI等组件。
2. 存储单元、存储示例
ppt第十章《工业互联网编程技术》第38页-39页,
存储单位有位(bit)、字节(Byte)、字(Word)、双字(DWord)
位(bit),是最小的存储单位,只能存储0或者1两种状态,编程时对于的触点通(1)、断(0),和线圈动作(1),不动作(0)。
字节(Byte),用B表示,8个bit组成,比如:QB0就表示Q0.0至Q0.7八个bit。
字(Word),用W表示,16个bit组成,也就是两个字节。比如QW0就是Q0.0至Q1.5这16个bit,也就是QB0和QB1组成,所以编程时,用了QW0,再用QB1,就会地址重复。或者用了QW0,就不能再用QW1,因为都包含了QB1这个字节。QW0中的0是起始字节编号。
双字(DWord),用D表示,32个bit,2个字,4个字节。同样道理,用了QD0,就说明占用了QB0、QB1、QB2、QB3四个字节。
数据存储示例:
3. 工业互联网网络传输安全问题
ppt第四章工业互联网的网络安全方法技术,第47页
工业互联网网络传输安全控制实现:
传输协议方面,应采用HTTPS、SSL/TLS、支持 IPSec 实现远程通道的安全加密,并对 IPv4 协议与 IPv6协议具有兼容性;
采用 SSL/TLS 来进行工业网络传输,保证其机密性、完整性与可用性:采用 HTTPS 协议,以 HTTP 作为通信机制,并使用 SSL/TLS 对传输的工业数据包进行加密,既能够实现网络服务器的身份认证,也能够为传输数据提供完整性与隐私保护;
工业互联网平台中各 VM 之间、VM 与存储资源之间、控制主机与各下位机之间,也需要采用数据加密通道。
根据工业现场的通信需要,可选择对安全通道数据始终加密或签名。如果远程用户请求域内网络数据资源服务,且该远程用户账户处于受信任安全域中,需要用户身份验证,验证通过后,获得数据库访问权限。
4. 工业互联网数据安全研究意义
ppt第六章工业互联网的数据安全方法与技术,第2页,
工业数据是工业互联网的一大基础资源,工业数据安全日渐成为工业互联网安全体系的核心、关键组成部分之一;
工业互联网愈发复杂,网络边界和数据维度不断扩张,为了促进工业数据资源高效整合,构建工业各业务流程数据链条闭环,需要对工业数据进行深入分析,综合考虑其产生、传输、存储、共享、应用以及销毁等全生命周期中的安全因素,构建工业数据的安全保障体系,采取相应的安全防护手段与措施,以防数据遭到泄露、篡改、破坏等威胁。
5. 工业数据的分类分级原则
ppt第六章工业互联网的数据安全方法与技术,第12页,
工业企业决策逐渐从“业务驱动”向“数据驱动”转变,数据信息联网与可用性成为工业数字化的核心。需要精确把握共享与安全二者之间的平衡
工业数据需要被多次使用,传统IT网络的隐私保护机制不具备现实可行性,数据信息隐私保护的责任将由数据使用方来承担。此时可采用的隐私保护手段包括数据分类分级和数据脱敏等
基于安全视角,工业数据的分类分级需要考虑的基本因素是共享需求、安全隐私保护、应用及保护成本,实现工业数据的类别划分和等级划分,并根据不同需求对关键数据重点防护
6.
ppt第十一章(中),工业互联网检测技术,P30,课后习题
DADD
1、基于流量的检测方式主要关注网络流量中的异常行为,以下哪项不属于典型的网络流量异常行为?
A. 大量的UDP数据包
B. 端口扫描
C. 恶意软件的下载
D. 重复出现的正常流量
2、基于设备状态的检测方法可以采用传统的异常检测算法,也可以结合机器学习等方法进行检测。以下哪种方法常用于设备状态异常检测?
A. 主成分分析
B. 朴素贝叶斯
C. 决策树
D. 神经网络
3、在数据预处理过程中,以下哪个步骤通常不是必要的?
A. 数据清洗
B. 特征选择
C. 特征提取
D. 数据标注
4、正常行为建模技术中,基于机器学习的方法通常需要进行训练集和测试集的划分。以下哪个不是划分方式?
A. 随机划分
B. 交叉验证
C. 时间序列划分
D. 特征选择
7. Modbus协议通信机制与分析
ppt第八章工业互联网通信协议与安全,P12页
Modbus协议帧:
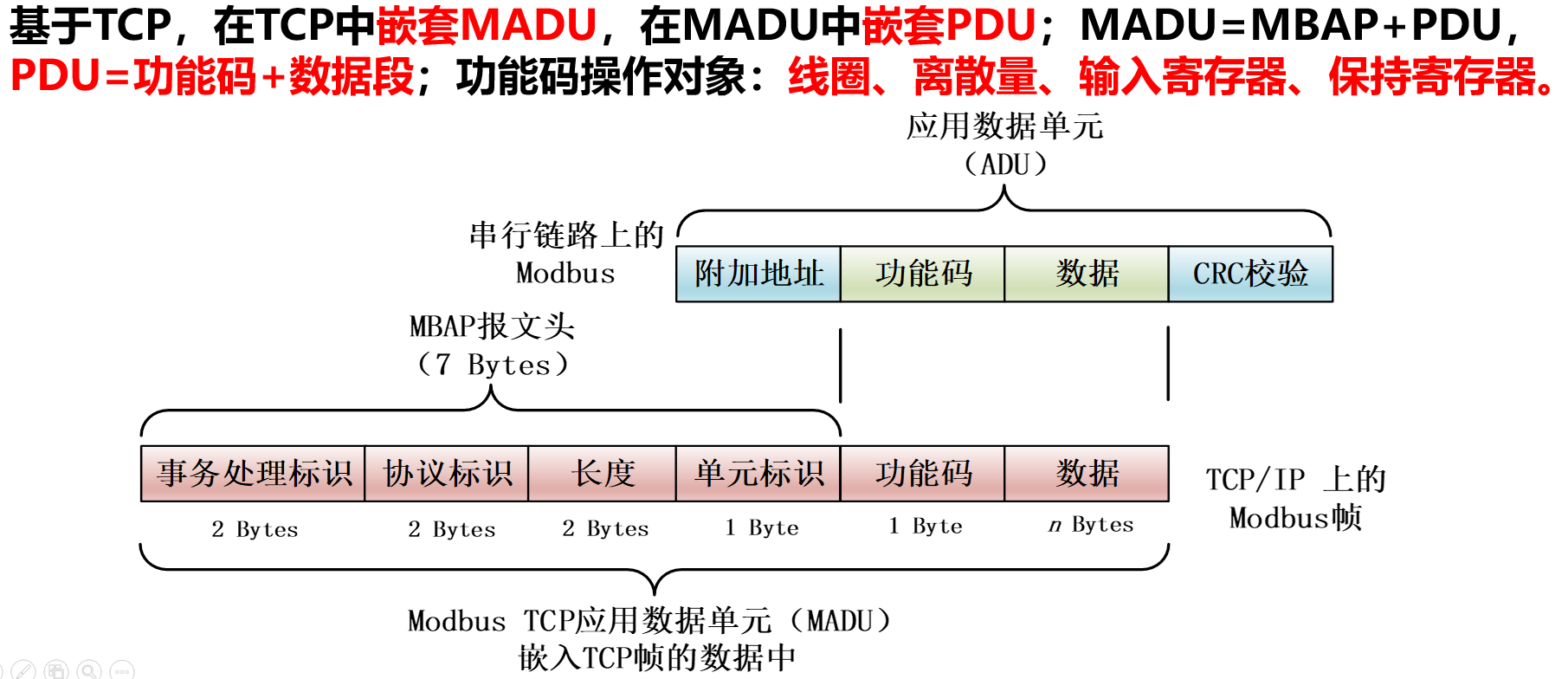
MBAP(报文头)各字段解释:
| 域 | 长度 | 描述 | 客户端 | 服务器 |
|---|---|---|---|---|
| 事务处理标识 | 2 Bytes | Modbus请求/响应事务处理 | 启动 | 从接收的请求中复制 |
| 协议标识 | 2 Bytes | 0*Modbus协议 | 启动 | 从接收的请求中复制 |
| 长度 | 2 Bytes | 后续字节的数量 | 启动 | 响应 |
| 单元标识 | 1 Bytes | 链路上连接的远程从站识别 | 启动 | 从接收的请求中复制 |
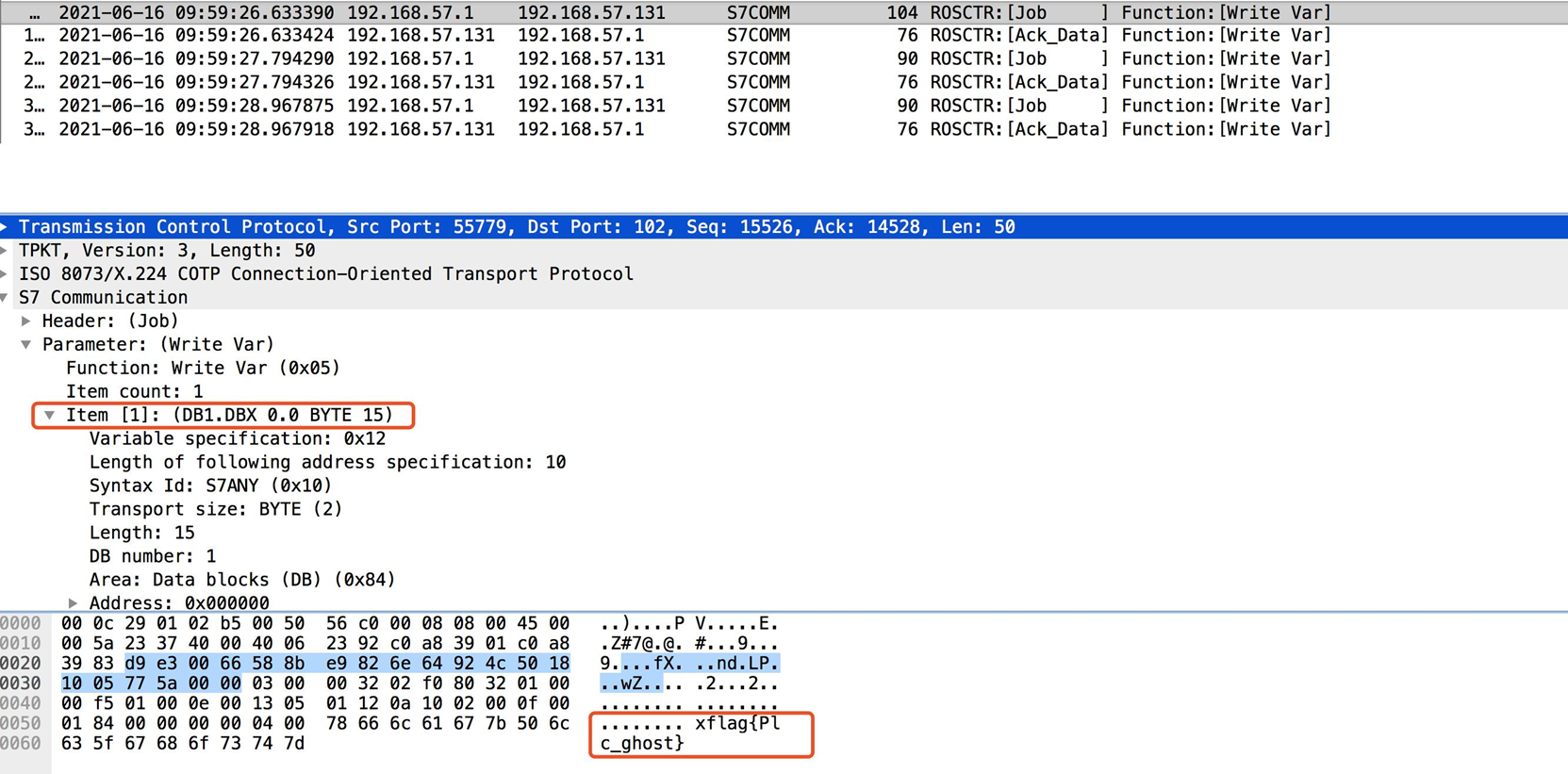
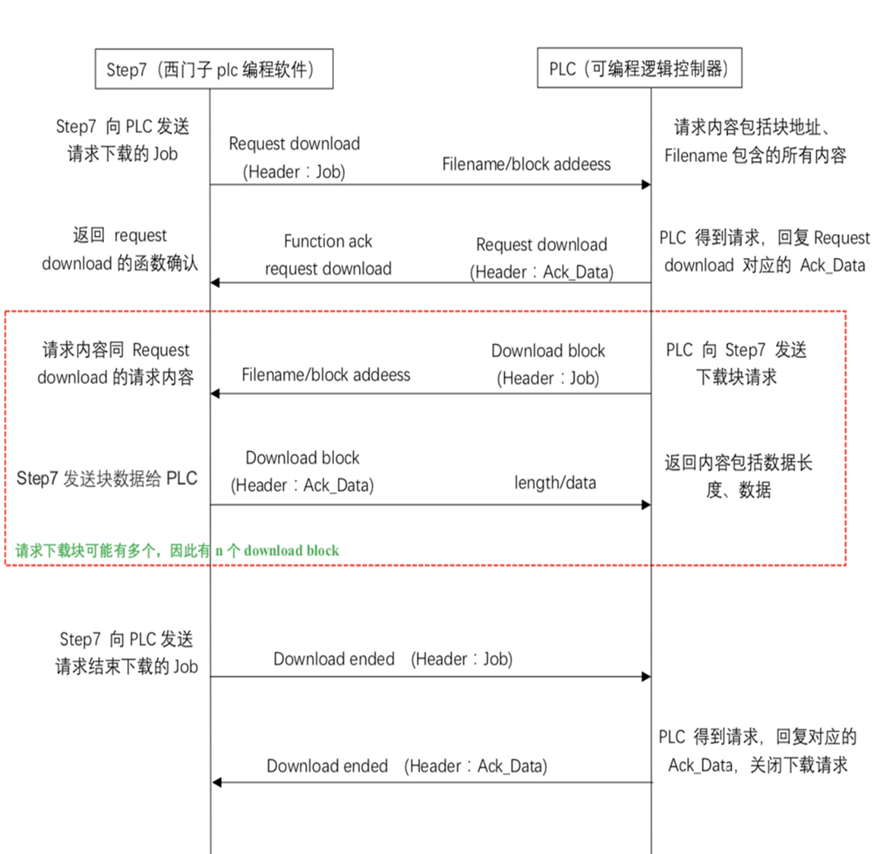
8. 基于S7协议的文件下载、上传
ppt第八章工业互联网通信协议与安全下,P9页。
基于S7协议的文件下载:
请求下载(Request download [0x1A])
下载块(Download block [0x1B])
下载结束(Download ended [0x1C])
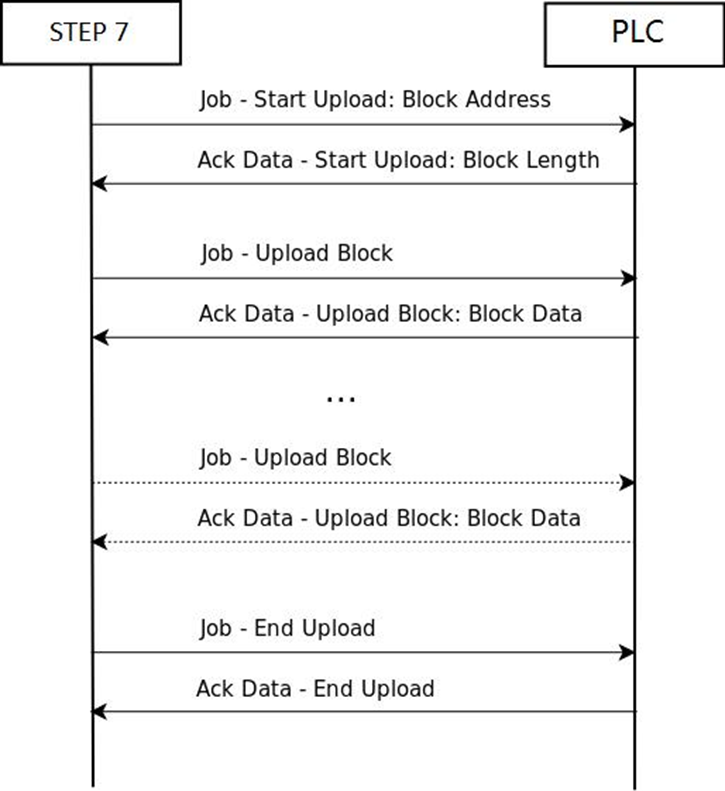
基于S7协议的文件上传:
上传(Upload)是PLC发送块数据给Step7
- Step7向PLC发送一个开始上传的Job;
- PLC收到后则回复一个 Ack_Data,并告诉Step7块的长度、上传会话ID;
- 然后PLC继续上传块数据到Step7,直到Step7收到所有字节;
- Step7发送结束上传的作业请求来关闭上传会话。
S7协议通信协议原理:
S7协议通信建立过程:
连接到TCP端口102上的设备;
在ISO层上连接(COTP连接请求);
在S7comm层上连接(s7com.param.func*0xf0,设置通信)。
步骤1:使用PLC/CP的IP地址;
步骤2:用作长度为2字节的目的TSAP。目的TSAP的第一个字节是通信类型(1PG,2OP)的编码。目的TSAP的第二个字节是机架和槽号的编码,这是PLC CPU的位置。槽号用0~4位编码,架号用5~7位编码;
步骤3:用于协商S7comme的特定细节(例如PDU大小)。
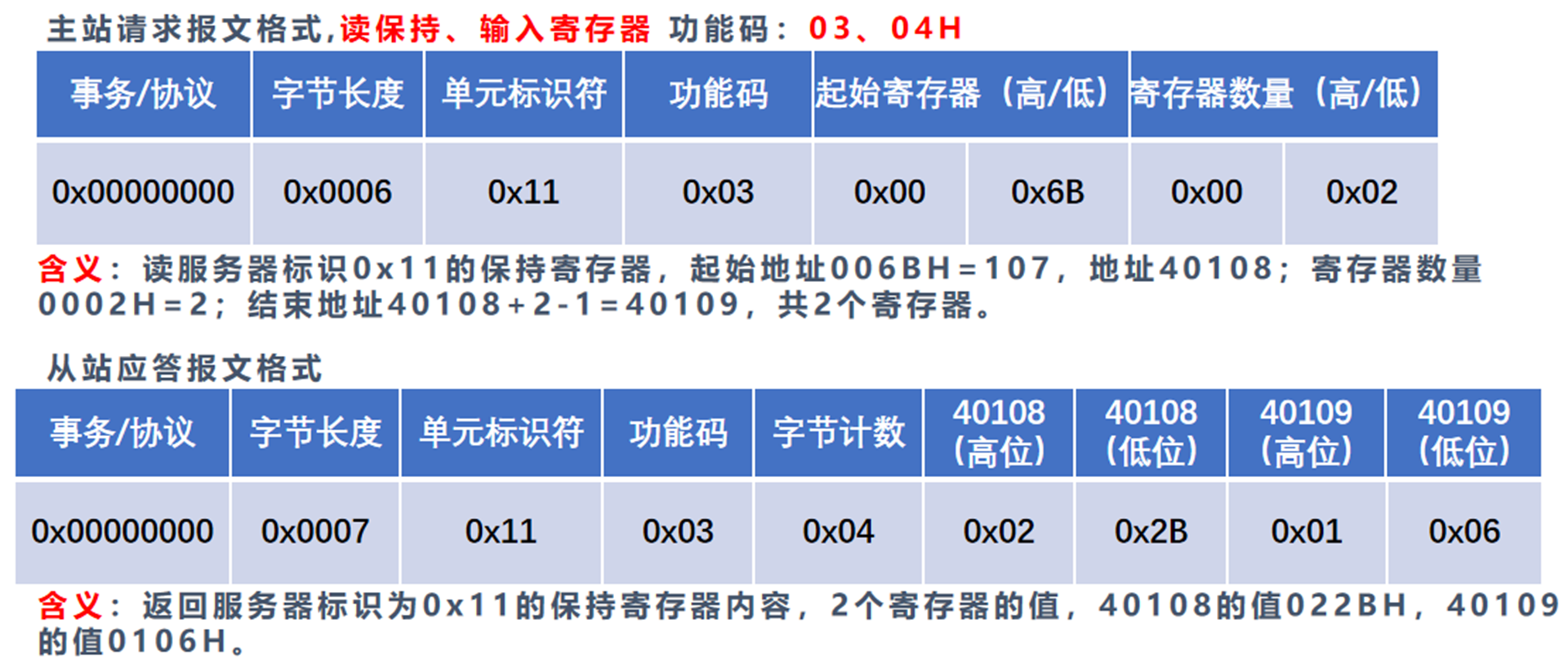
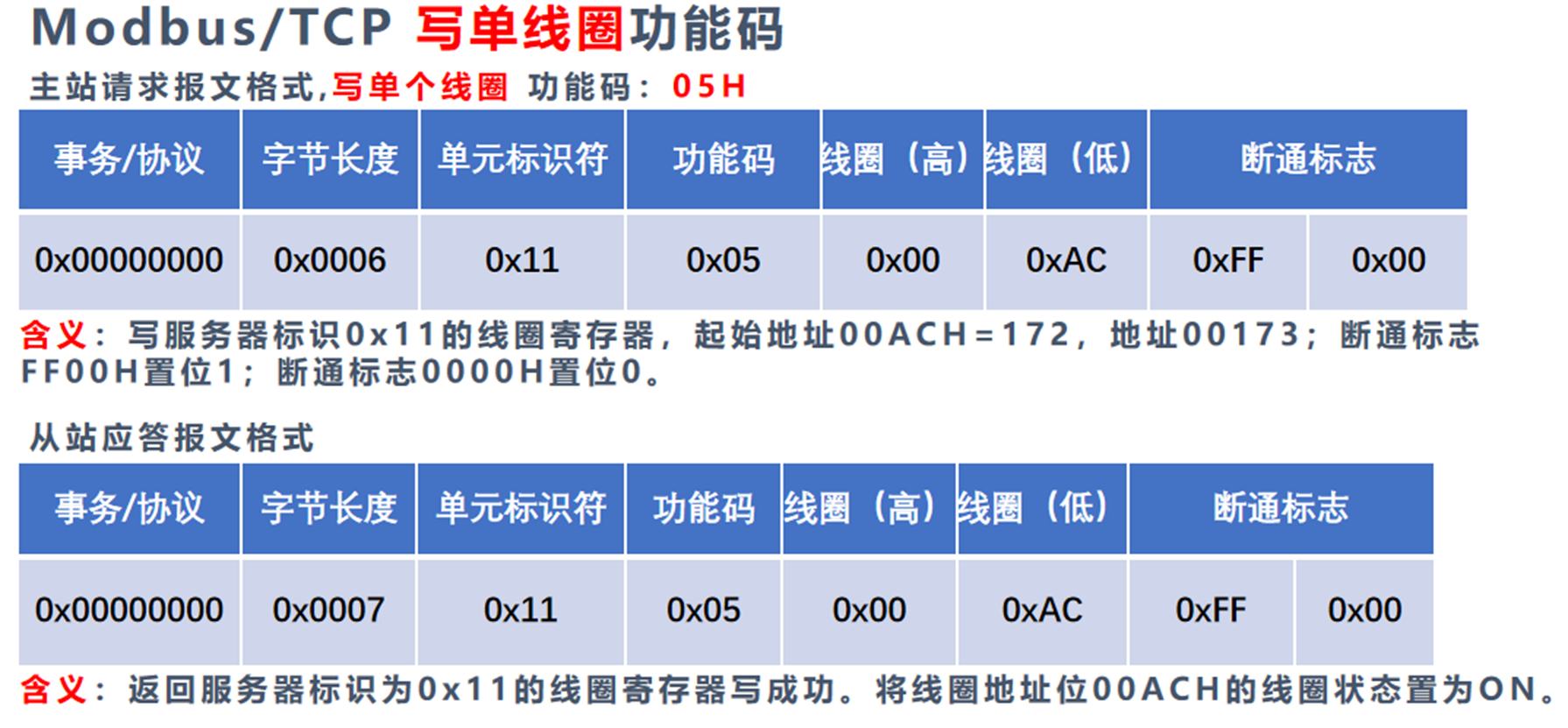
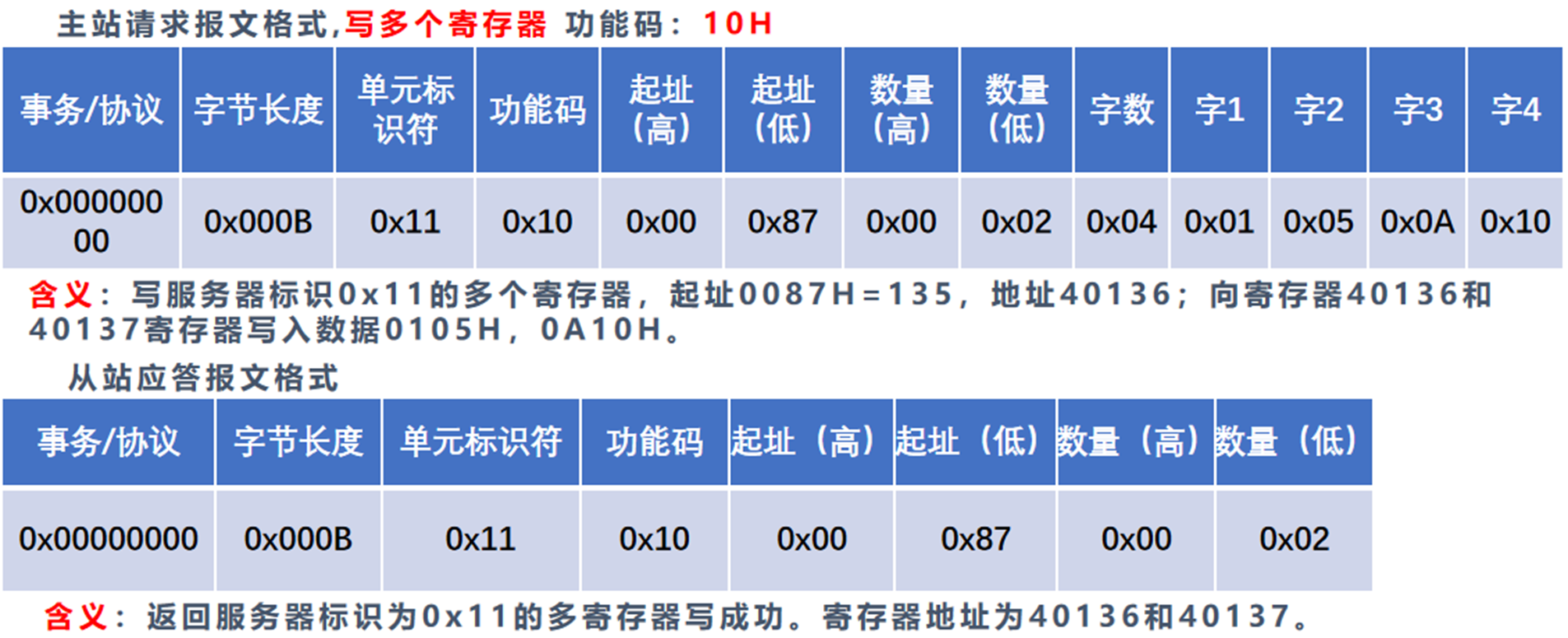
9. Modbus典型功能码操作
ppt第八章工业互联网通信协议与安全,第19页,
10. 安全监控和日志记录
ppt第九章工业互联网安全防御,第20页,
工业互联网网络被充分划分网段,安全控制就可以跨安全区域分布,通过添加监控功能来减少(持续)危害的风险,从而提高网络和主机活动的可见性。
根据控制需求,必须设计遍历IDMZ的功能。例如,工业区中的日志聚合解决方案需要在企业区之间建立管道以发送信息或接收指令。
网络和安全监视以及日志记录信息的两个主要来源是网络数据包捕获和事件日志。
11. 定时器和计数器指令,比较操作指令
ppt第十章工业互联网编程技术(中),第20页,第27页,P30页,
定时器根据时钟脉冲(常见的时钟脉冲有 100ms、10ms 和 1ms)的累积来实现定时,它在程序中主要起延时作用。当累积的脉冲个数达到设定的数值时,定时器对应的触点开始动作。

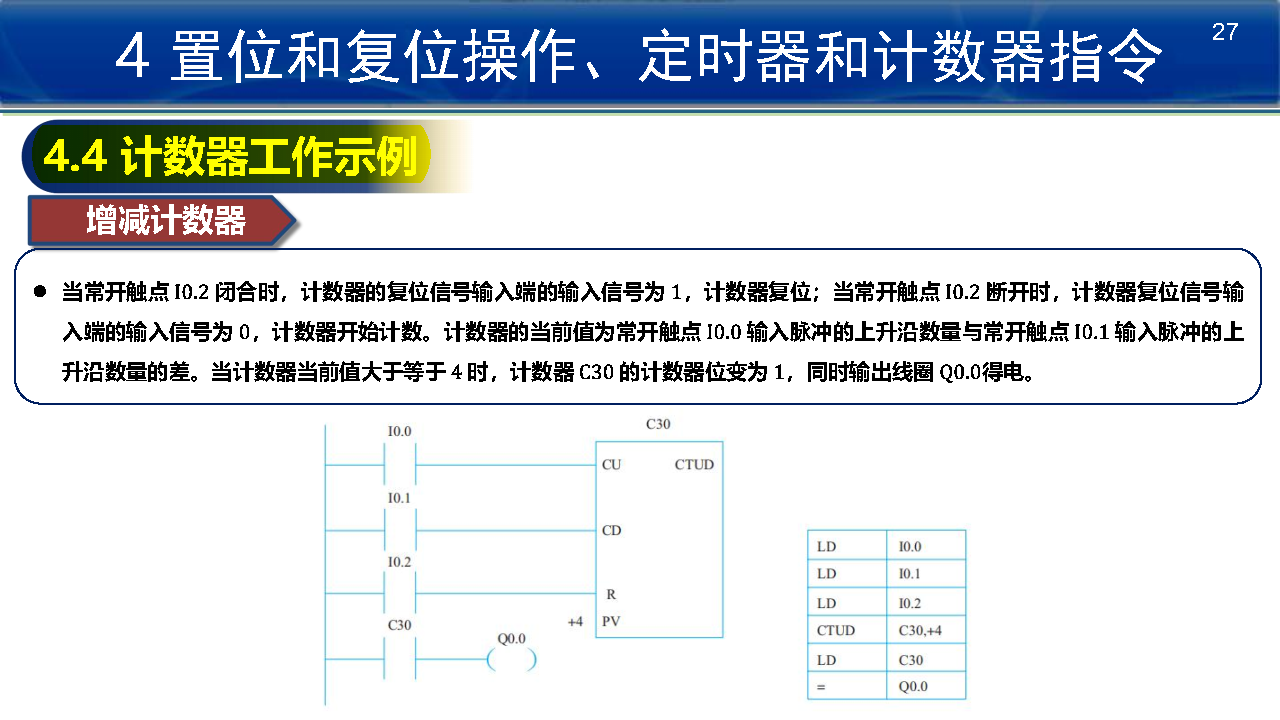
计数器与定时器的结构和原理相似,其功能是累计输入脉冲的次数。当执行计数器指令时,需要先设定一个预设值,然后计数器开始对输入脉冲进行计数。当计数器的当前值达到预设值时,计数器发送中断请求,并使 PLC 做出相应动作。
计数器编号用计数器名称和数字(0 ~ 255)组成,计数器编号 Cn 包含计数器位和计数器当前值。其中,计数器位根据满足的条件将计数器状态置 1 或置 0;
计数器当前值用来保存累加的脉冲数,用 16 位符号整数来表示。在西门子 PLC 编程手册中,规定其取值范围为 -32767 ~ 32767。
- 增计数器:CTU
- 减计数器:CTD
- 增减计数器:CTUD
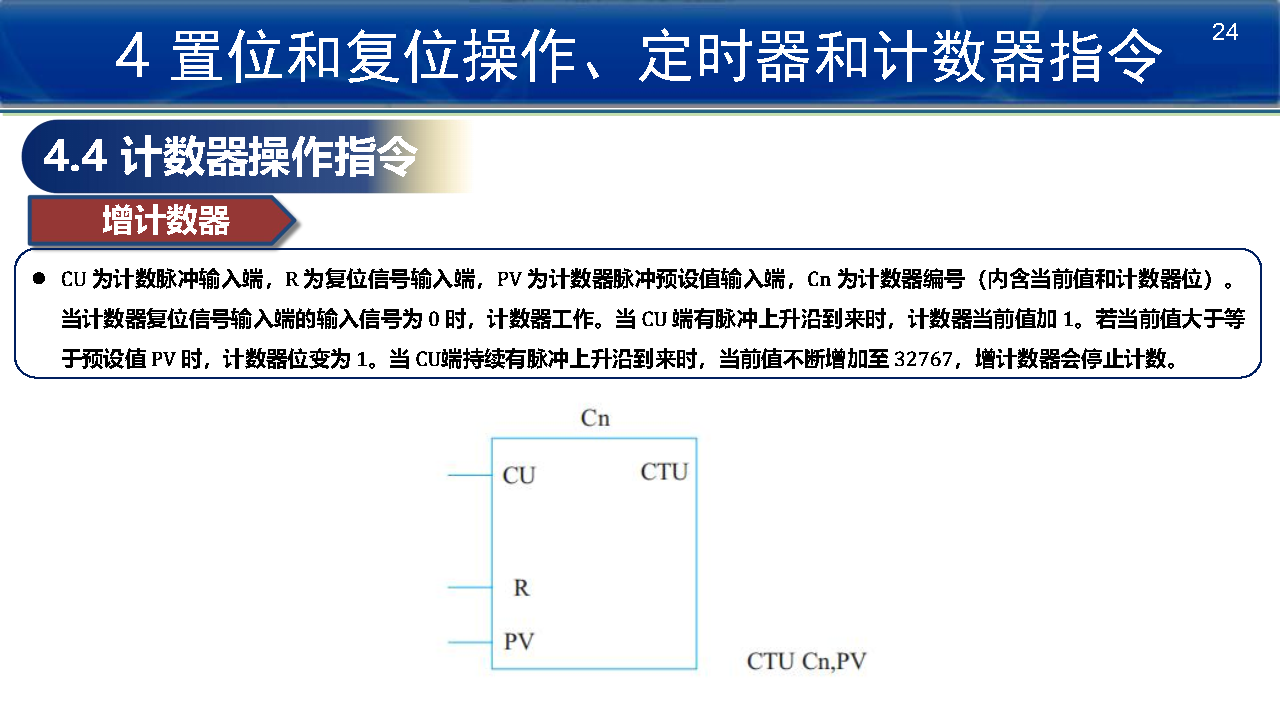


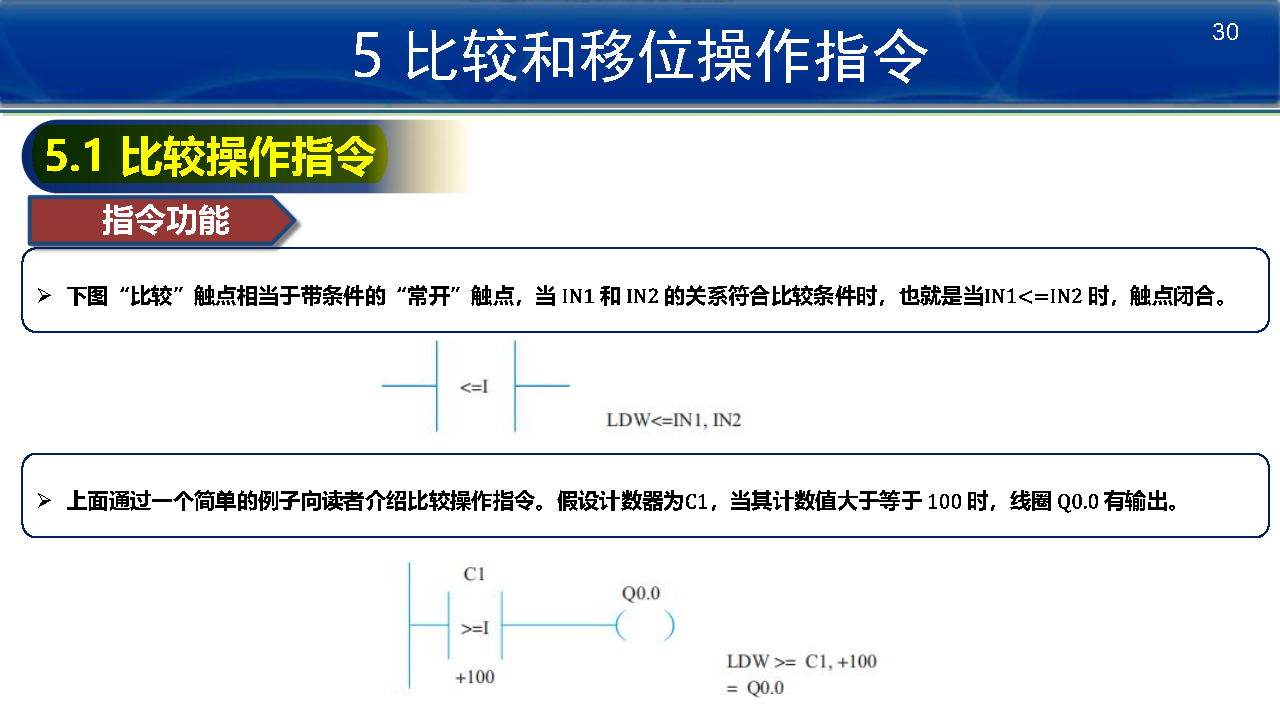
比较操作指令:
比较操作指令可实现字节(无符号)、整数(带符号)、双字整数(带符号)、实数(带符号)等数值的比较。
使用比较操作指令可轻松实现数值条件的判断和上下限的控制:(等于)、>(不小于)、<*(不大于)、>(大于)、<(小于)和 < >(不等于)。对于不同品牌的 PLC,其指令符号块的表示符号可能不同。例如,台达PLC(Delta PLC)使用“-”表示比较操作指令符号块。
梯形图中的数据类型有 B(字节)、I(整数)、D(双整数)和 R(实数)。
指令表中的数据类型有 B(字节)、W(整数)、D(双整数)和 R(实数)。
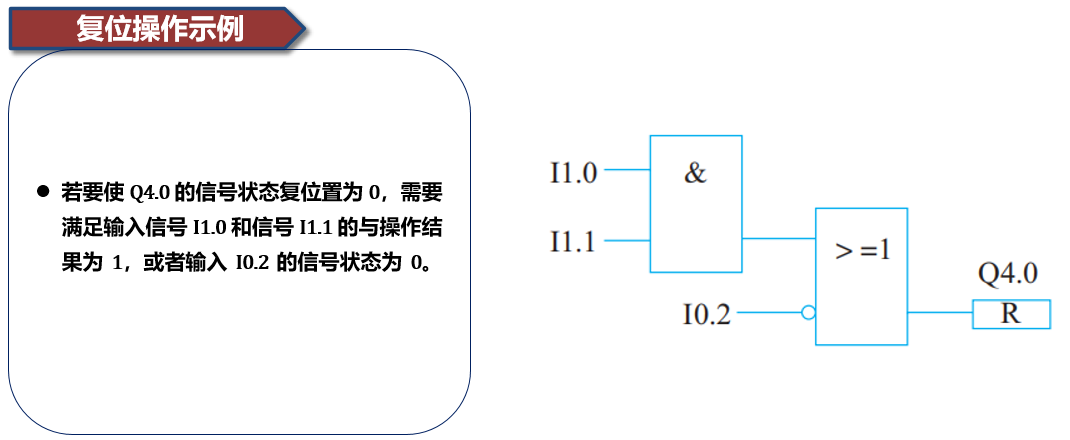
12. 逻辑运算功能块图,复位操作示例
ppt第十章工业互联网编程技术(下),第9页,
13. 跳转和标号指令
ppt第十章工业互联网编程技术(中),第38、39、41、42、43页。
程序控制操作指令:
程序控制操作指令主要分为有条件结束指令、停止指令、看门狗复位指令、循环指令、子程序指令等。
执行有条件结束指令时,系统结束主程序,并返回到主程序的起点。
--(END)执行停止指令时,其状态从运行(RUN)模式进入停止(STOP)模式,并立即终止程序的执行。
--(STOP)执行看门狗复位指令可对 PLC 内部设置的看门狗定时器(Watch Dog Timer,WDT)进行复位。WDT 用来监视 PLC 的扫描周期是否超时,每当系统扫描 WDT 时,只有 WDT 及时复位才能持续监视 PLC 的扫描周期是否正常。当系统正常工作时,如果所需的扫描时间小于 WDT 的设定时间,则 WDT 能够及时复位。如果系统发生故障,扫描时间大于 WDT的设定时间,WDT 就不能及时复位,并会发出错误报警,停止 CPU 运行。
如果希望系统扫描时间超过 WDT 的设定时间,或者预计在执行程序时会遇到大量中断、循环指令导致扫描时间过长,在 WDT 设定的时间内无法返回到主程序,并且在这些情况下 WDT 不能动作,那么可以使用看门狗复位指令,重新触发 WDT 使其复位。
--(WDR)
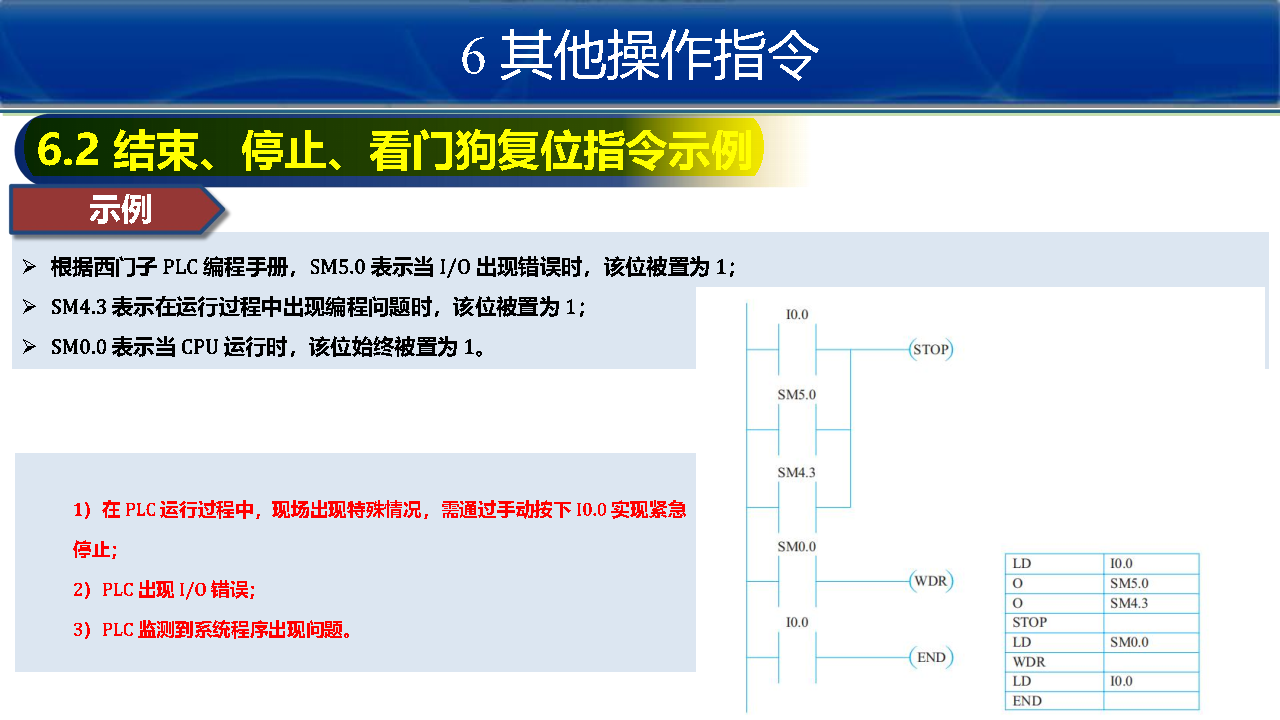
结束、停止、看门狗复位指令示例:
使用 END、STOP 或看门狗复位(WDR)指令,可保障 PLC 的停止。当出现以下三种情况时,会执行 STOP 停止指令,从而停止 PLC,防止事故发生:
在 PLC 运行过程中,现场出现特殊情况,需通过手动按下 I0.0 实现紧急停止;
PLC 出现 I/O 错误;
PLC 监测到系统程序出现问题。
解决方法:
当执行程序遇到大量循环指令或者中断指令时,虽然 PLC 能正常运行,但会延长 PLC的扫描周期而导致 WDT 故障。为防止 WDT 故障,可在适当位置增加 WDR,使 WDT 复位;
若在 PLC 运行过程中不想执行某一段程序,那么可以在不希望执行的程序段前增加 END 指令。这样,只要执行 END 指令,PLC 就会返回到主程序的起点,重新执行主程序而跳过不想执行的某段程序。
跳转和标号指令:
在程序执行时,可能需要根据不同的条件选择一些程序分支来执行,这时就要用到跳转和标号指令,以选择执行不同的程序段。跳转指令需要与标号指令配合使用,而且只能出现在同一程序块中(例如主程序、同一个子程序或中断程序),而不能在不同的程序块间相互跳转。--(JMP) JMP n
循环指令:
当 PLC 遇到需要反复执行若干次具有相同功能的程序时,可以使用循环指令,以提高编程效率。循环指令由循环开始指令 FOR、循环体和循环结束指令 NEXT 组成:
FOR 指令表示循环开始,NEXT 指令表示循环结束,中间为循环体。

14.
ppt第十一章(中),工业互联网检测技术,P30,课后习题。
15. 基于安全架构的5A方法论
ppt第十三章安全技术体系架构,第55页。
基于安全架构的5A方法论:
- 身份认证:是否集成SSO。
- 授权:主要关注权限管理系统。
- 访问控制:主要关注应用接入。
- 审计:主要关注统一的日志管理平台。
- 资产保护:包括数据脱敏与加解密、WAF、业务风控、客户端数据安全等。
三、简答题
1. 工业互联网的网络访问控制方法
ppt第四章
制定并实施工业网络访问控制策略,需要根据最小特权原则、最小泄露原则以及多级安全策略来规范访问主体、客体与访问控制列表(Access Control List,ACL)的关系。
访问控制的具体手段有:
- 用户识别码
- 口令
- 登录控制
- 资源授权
- 授权核查
- 日志和审计等
工业互联网适用的网络访问控制模型:
在工业网络访问控制中,常采用自主访问控制(Discretionary Access Control,DAC)、强制访问控制(Mandatory Access Control,MAC)以及基于角色的访问控制(Role-Based Access Control,RBAC)。
工业互联网自主访问控制及其适用性:
DAC 允许主体显式指定其他主体(合法用户)以用户或用户组的身份对该主体所拥有的信息资源是否可以访问及执行,具体有基于主体和基于客体两种实现机制。
DAC的三大缺点:
一是工业网络资源管理较分散,难以体现用户之间的关系;
二是工业网络资源所有者可自主向其他主体授予权限,易导致权限传递失控;
三是 DAC 需要对每个数据指定用户及权限,而工业互联网中,用户和数据数量较大,导致 DAC 系统开销变大,用户角色变更需要修改其访问权限,授权管理困难。DAC 对工业互联网的适用性不强!
工业互联网的网络强制访问控制及其适用性:
MAC 预先为访问主体和受控客体设定不同的安全级别属性,以梯度安全标签来控制数据单向流动,依据主体和客体的安全属性级别来决定主体是否拥有对工业网络资源的访问权限。
优缺点:
按照预设安全级别实现了严格的权限集中管理,通过数据的单向流动可防范数据扩散,增强信息的机密性,可抵御病毒、木马等恶意代码攻击;
用户和数据的安全级别分别取决于用户的可信任级别及数据的敏感程度,在访问控制粒度上不满足最小特权原则要求,主、客体安全级别的划分与现实情况并不相同,同级别之间缺乏控制机制,不便管理,无法实施全面的数据完整性控制;
在工业互联网中,存在着大量的共享存储器、Cache 等逆向潜信道,可导致数据不遵循 MAC 规则流动,存在潜在的安全隐患。
基于角色的工业互联网网络访问控制:
为用户分配特定角色,并在用户与角色之间建立多对多映射关系。同时,为角色分配特定的访问权限,以角色为媒介将用户与访问权限相关联,在角色与访问权限之间构建多对多映射关系。
优缺点:
RBAC 简化了各种应用场景下的授权管理,满足最小特权原则;角色保持相对稳定,当用户变化时,只需要撤销和重新分配角色。
责权分离容易将攻击者的关注点从原来的用户转向角色,存在带来更大的安全隐患的潜在可能。为一个用户指定多种角色、将工业网络资源指定到多个访问组,一旦配置错误,易导致用户权限过大。
2. 隐私保护增强技术,分析不同隐私保护增强技术的优缺点
隐私保护是数据安全中的一个重要部分。除需要满足数据安全要求外,还要满足适用的法律法规要求。满足内部的要求可称为内部合规,满足法律法规的要求就是外部合规。
隐私保护的技术手段:
- 身份认证(Authentication):用户主体是谁?
- 授权(Authorization):授予某些用户主体允许或拒绝访问客体的权限。
- 访问控制(Acccess control):是否放行的执行者。
- 可审计(Auditable):形成可供追溯的记录。
- 资产保护(Asset protection):资产的保密性、完整性、可用性保障。
通用的数据保护技术:==存储加密、传输加密、展示脱敏等==。这些技术也同样适用于对个人隐私的保护。
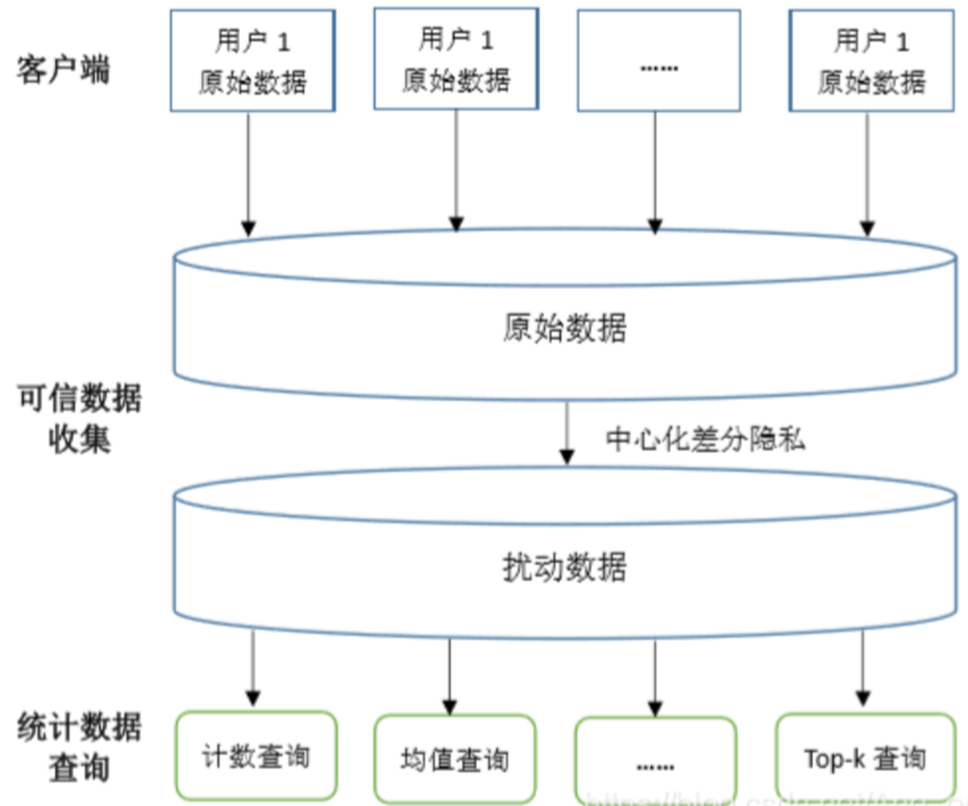
当用于保护个人数据的时候,还需要一些专用的技术,==包括去标识化、差分隐私等,这些技术统称为PET(Privacy Enhancing Technologies,隐私增强技术)==。
1)去标识化
匿名化(含K-匿名)
K -匿名:它通过引入等价类的概念,要求发布的数据中k条记录为一组,其中的每一条记录都要与其他至少k-1条记录不可区分(这k条记录相似,称为一个等价类)。保障每条隐私数据都能找到相似的数据,从而降低单条数据的识别度。
使用场景主要是数据集发布或数据集提供给第三方研究机构。
k值越大,隐私保护的强度越强(任何一条疑似某人的记录,都可以再找到k-1条相似的记录)。
k值越大,丢失的信息更多,数据的可用性就越低(一些比较罕见的样本如果无法凑成一个等价类就不能用了)。
当拿到K -匿名处理后的数据时,将至少得到k个不同人的记录,进而无法做出准确的判断;也就是说,任何一条记录,都可以再找到k-1条相似的记录。
但这仍存在缺陷,如果一个等价类中的多个样本都是同一种疾病(比如乙型肝炎),则所涉及的几位自然人的隐私就泄露了,可能会被周围认识的人高度怀疑其患了该病,称之为一致性攻击。
为了防止一致性攻击,L-Diversity(L-多样性)隐私保护模型在K -匿名的基础上,要求保证任意一个等价类中的敏感属性都至少有L个不同的值。
如果在一个等价类中,疾病种类小于L,则这个等价类中的记录就不能使用。因为,只有一个人患该病的话,也会造成该患者的隐私泄露,至少需要在一个等价类中为其找到L-1个病友(行记录),才能降低其中每一患者隐私泄露的风险。
就算满足L-Diversity,仍有可能导致隐私泄露,假如有一个敏感字段为HIV筛查结果(阳性、阴性),可以达成2-Diversity,但这个多样性其实没有意义,无论结果是阴性还是阳性,记录出现在这个数据集本身就造成部分隐私信息泄露。
假名化(使用假名替换真名)
对可标识的用户身份信息用假名替换。但是需要了解的是,假名化的数据,仍是有很大概率找出对应的自然人,难以达到去标识化的目的,所以假名化的数据仍将被视为个人数据,需要跟明文数据一样加以保护。
上面提到的删除姓名或使用假名,虽无法直接标识用户,但攻击者还是有可能通过多个属性值,结合其他已知的背景知识,识别出真实的个人,从而导致自然人的隐私数据泄露。
2)差分隐私
差分隐私:其原理是在原始的查询结果(数值或离散型数值)中添加干扰数据(即噪声)后,再返回给第三方研究机构;加入干扰后,可以在不影响统计分析的前提下,无法定位到自然人,从而防止个人隐私数据泄露。
差分隐私原理:为防止攻击者利用减法思维获取到个人隐私,差分隐私提出了一个重要的思路:在一次统计查询的数据集中增加或减少一条记录,可获得几乎相同的输出。也就是说任何一条记录,它在不在数据集中,对结果的影响可忽略不计,从而无法从结果中还原出任何一条原始的记录。
差分隐私的概率表达:选用不同的输入(D),输出(V)也会不同,我们用P()表示A(D)
= V的概率,则对于所有的输出V,要求:
按处理位置的分布,差分隐私可分为:
本地化差分隐私:当隐私数据从用户侧采集时(比如手机APP),如用户的浏览记录,按就近处理的原则,使用本地差分隐私,将本地的抽样统计数据加入噪声后再上传。
从本地缓存数据中抽样统计,添加噪声后,再将抽样统计结果提交到后端服务器。

中心化差分隐私:传统的差分隐私是将原始数据集中到一个数据中心,然后在此对数据施加差分隐私算法,并对外发布,称之为中心化差分隐私(Centralized Differential Privacy)。
当隐私数据存在于服务器侧交互式查询接口时,如医疗数据,按就近处理的原则,使用中心化差分隐私,查询结果添加噪声后再提供。
中心化差分隐私有一个前提:可信的第三方数据收集者,即保证所收集的数据不会被窃取和泄露。然而,在实际生活中想找到一个真正可信的第三方数据收集平台十分困难,这极大地限制了中心化差分隐私的应用。
3. Snort相关
Snort是一款集数据包嗅探、数据包记录、网络入侵检测三个功能于一体的跨平台、轻量级、开源、免费网络安全工具,其具有二次开发的模块化架构,允许开发人员在不修改核心代码的情况下加入各种自定义插件以扩展功能。
功能描述
- 数据包嗅探功能:最基本的功能,捕获网络通信中的数据包,进行协议解析,根据协议类型实现数据包数量统计功能。该功能基于libpcap实现,类似于数据包捕获工具Wireshark。被控制端的应用程序非常短小,便于上传。
- 数据包记录功能:将上述捕获的数据包存储到本地硬盘中,并对其进行分析处理。默认情况下snort将捕获的数据包保存在/var/log/snort目录下。
- 入侵检测功能:通过将捕获的数据包与检测规则匹配,发现入侵行为,并根据命中规则中定义的动作,如Alert、Activate、或Pass做出相应的处理。
snort规则
snort规则用于描述异常流量的特征以及当数据包与规则相匹配时的响应措施。Snort规则可分为两个部分:规则头和规则体。
- 规则头:包含规则动作(action)、协议,源IP地址/掩码与源端口号、方向操作符、目标IP地址/掩码与目标端口号。
- 规则体:由许多可选择的规则选项组成,包含报警消息内容和要检查的包的具体部分。
示例:括号前的部分是规则头,括号内的部分是规则体,规则体部分中冒号前的单词称为选项关键字:
1 | |
不是所有规则都必须包含规则体部分,规则体部分相当于规则头的补充,可以更深入的过滤数据包的内容。当定义的多个选项组合在一起时,认为它们组成了一个逻辑与(AND)语句。snort规则库文件中的不同规则可以认为组成了一个大的逻辑或(OR)语句。
规则动作
在snort中有五种动作:alert、log、pass、activate和dynamic。目的是告诉snort在发现匹配规则的包时要干什么。
- Alert:使用选择的报警方法生成一个警报,然后记录(log)这个包。
- Log:记录这个包。
- Pass:丢弃(忽略)这个包。
- activate:报警并且激活另一条dynamic规则。
- dynamic:保持空闲直到被一条activate规则激活,被激活后就作为一条log规则执行。
协议
指出这条规则所检查的数据包协议类型。目前Snort支持的协议有四种:TCP、UDP、ICMP和IP等。如果需要对应用层协议进行进一步分析,则需要使用规则体选项。
IP地址
关键字“any”可以被用来定义任何地址,地址就是由直接的数字型IP地址和一个CIDR块组成的。
CIDR块:作用在规则地址和需要检查的进入的任何包的网络掩码。/24表示c类网络,/16表示b类网络,/32表示一个特定机器地址。
否定运算符:(“!")应用在ip地址上,表示匹配除了列出的ip地址以外的所有ip地址。
示例:
192.168.1.0/24代表从192.168.1.1到192.168.1.255的地址块。在这个地址范围的任何地址都匹配使用这个192.168.1.0/24标志的规则。
对任何来自本地网络以外的流都进行报警,这个规则的ip地址代表“任何源ip地址不是来自内部网络而目标地址是内部网络的tcp包”。
1
alert tcp !192.168.1.0/24 any -> 192.168.1.0/24 111 (content: "|00 01 86 a5|"; msg: "external mountd access";)可以把IP地址和CIDR块放入方括号内“[”,“]”来表示IP地址列表。
1
alert tcp ![192.168.121.0/24,10.1.1.0/24] any -> [192.168.121.0/24,10.1.1.0/24] 111 (content: "|00 01 86 a5|"; msg: "external access";)
端口号
端口号可以用几种方法表示,包括"any"端口、静态端口定义、范围、以及否定操作符。
- “any”端口:是一个通配符,表示任何端口;
- 静态端口:定义表示单个端口号,例如:111表示portmapper,23表示telnet,80表示http等等;
- 端口范围:用范围操作符“:”表示,范围操作符可以有数种使用方法,如:log udp any any -> 192.168.1.0/24 1:1024;表示记录来自任何端口的,目标端口范围在1到1024的UDP流;
- 否定操作符:用法与IP地址的否定操作符用法类似。
方向操作符:
->:表示规则所检查的流量方向。方向操作符左边的IP地址和端口号被认为是流来自的源主机,方向操作符右边的IP地址和端口号是目标主机。<>:表示双向操作符,指示Snort把地址/端口号对既作为源,又作为目标来考虑。
规则体
规则体由许多可选择的规则选项组成,它是snort入侵检测引擎的核心。所有的snort规则选项用分号";"隔开。规则选项关键字和它们的参数用冒号":"间隔、不同参数之间使用“,”间隔。按照这种写法,snort中有42个规则选项关键字。
| 关键字 | 功能 |
|---|---|
| msg | 在报警和包日志中打印一个消息。 |
| logto | 把包记录到用户指定的文件中而不是记录到标准输出。 |
| ttl | 检查ip头的ttl的值。 |
| tos | 检查IP头中TOS字段的值。 |
| id | 检查ip头的分片id值。 |
| ipoption | 查看IP选项字段的特定编码。 |
| fragbits | 检查IP头的分段位。 |
| dsize | 检查包的净荷尺寸的值。 |
| flags | 检查tcp flags的值。 |
| seq | 检查tcp顺序号的值。 |
| ack | 检查tcp应答(acknowledgement)的值。 |
| window | 测试TCP窗口域的特殊值。 |
Snort由数据包捕获模块、解码模块、预处理模块、检测引擎和告警输出等五个模块组成。
数据包捕获模块:从网卡中捕获工控系统中的网络流量,将其捕获后发送到数据包解析模块;
数据包解析模块:依据数据包的协议类型从链路层到应用层进行逐层解码;
预处理模块:除了可以调用自身功能外,还允许用户扩展其功能。其具备分片数据包重组、数据包规格化处理、或检测某些入侵行为,如检测BO后门流量、检测端口扫描攻击流量、ARP协议攻击等功能。用户功能扩展时,首先编写预处理插件,然后在配置文件中对其注册,注册成功后,每个进入预处理器模块的数据包会被所有预处理器插件处理;
检测引擎:通过规则文件实现检测功能,Snort运行后,将规则文件中所有规则存储为一个链表判定树结构。检测规则的规则头存储为规则树结点,该条规则体中各个规则选项存储为规则选项结点,并按顺序链式存储起来,规则选项结点存储为规则树结点的孩子,具有相同规则动作的规则树结点也以链式存储起来;
将数据包逐个通过alert至sdrop规则动作的链表判定树。如果数据包与当前规则树结点不匹配,则可以方便的将其与当前规则树结点相连的下一条规则树结点进行匹配。如果可以匹配成功,则继续与规则树结点相连的规则选项结点进行匹配,当所有规则选项结点都能与之成功匹配时,则触发相应动作。
告警输出模块:负责将告警输出到日志文件、套接字或数据库等。
snort检测原理
Snort属于基于误用的入侵检测系统。内置随机森林异常流量检测模型的 Snort 预处理器,通过对Snort的重新编译和配置,实现了 Snort与机器学习分类模型的结合,进而扩展了Snort的检测能力,使之具备部分未知攻击检测能力。其基本原理如下:
- 采集包含正常流量与异常流量的原始系统流量;
- 采用深度包解析技术从工业协议中抽取出关键特征;
- 建立标注了正常流量和异常流量类型的训练数据集和测试数据集;
- 使用监督学习或无监督学习算法,如支持向量机、决策树、随机森林、朴素贝叶斯分类器、k近邻等算法,选择测试集效果最好的一种模型作为最优的入侵检测模型;
- 基于新型Snort预处理器,该处理器执行工业协议深度包解析功能,并提取出模型所需的各项特征,将特征输入4)所选择的入侵检测模型中,对其流量种类进行判断,并将异常结果反馈给Snort预处理器,预处理器调用告警模块API输出告警信息。
四、大题
1. 代码安全审计
对MES系统中如下图所示的一段代码进行安全审计:

- 请确定漏洞的类型;
漏洞类型:路径遍历漏洞(Path Traversal)和服务端注入漏洞。
- 请指出存在漏洞的代码行号,并描述可能造成的影响;
第 3 行:filename * request.json.get("name")。在这一行中,应当对用户输入进行严格的验证和过滤,以防止恶意用户提交恶意文件名或路径。如果未对用户输入进行适当的过滤,可能导致路径遍历漏洞,使得攻击者可以通过在"name"字段中输入恶意路径来访问服务器上的任意文件,包括敏感文件,甚至可能执行恶意代码。
第 4 行:file * f"{abs path}/{filename}"。在这一行,虽然尝试构造文件路径,但未对路径进行安全验证,可能导致恶意用户构造的路径攻击。如果攻击者能够控制文件名,可能导致路径遍历漏洞或者在不安全的目录下访问敏感文件,造成信息泄露或系统被入侵的风险。
第 14 行到第 18行:这一段代码中,应该在返回文件内容之前,先验证文件的合法性和用户的权限。在这段代码中,如果文件存在,则直接返回文件内容,但没有对文件类型进行验证和安全过滤。这可能导致服务端注入漏洞,允许攻击者通过构造恶意文件来执行任意代码,从而危害服务器安全。
综上所述,这段代码存在路径遍历漏洞和服务端注入漏洞,可能导致信息泄露和服务器被入侵。修复建议包括严格验证和过滤用户输入,确保文件路径的合法性,并且在返回文件内容之前进行文件类型的验证和安全过滤,以防止服务端注入漏洞。
2. 梯形图阅读
对PLC程序破坏事件进行分析,任务文件名为“LadderLogic-schneider.zip”, 完成以下任务:
由智能装配场景可知,机座打螺丝工作站中的打螺丝数量是由PLC中的梯形图逻辑控制,现MW102点位受到攻击被篡改为88,当正常启动系统M10点位后,计算非法打螺丝数量MW200的数值。
首先对程序进行分析:
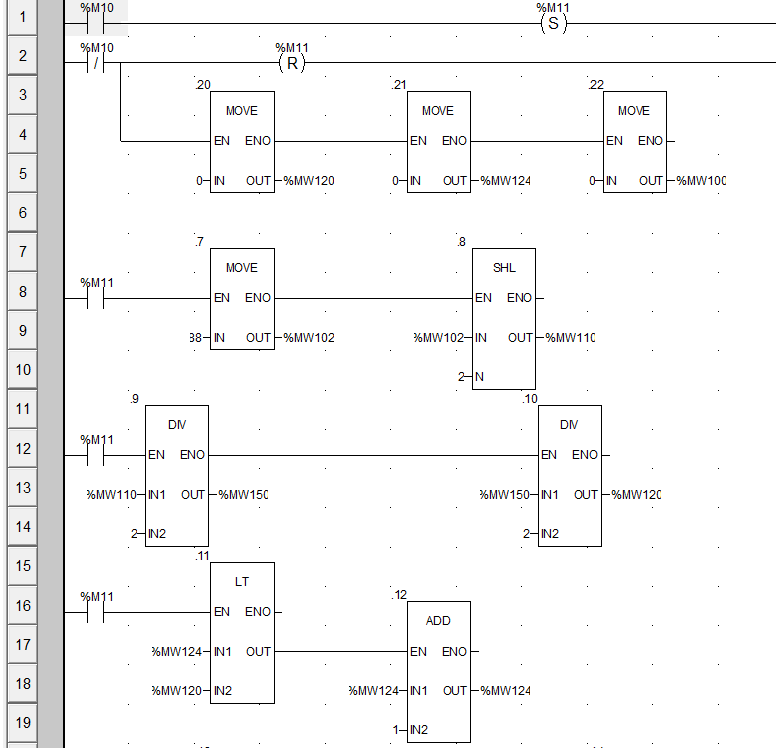
在第4行,使用三个MOVE指令为MW100、120、124均赋值为0;
在第8行,将MW102赋值为88;使用SHL(Shift left)向左移位指令,输入为MW102,移动2位,输出为MW110的值,即352;
在第12行,使用DIV(Division)除法指令,将MW110的值除以2,得到176,结果存储在MW150中;使用第二个除法指令,将MW150除以2,得到88,存储在MW120中;
在第17行,使用LT(Less than)指令,将MW124和MW120的值进行比较,用结果使能下一条ADD指令。由于MW124初始值为0,小于IN2端口的输入88,因此LT的OUT输出为1,ADD指令生效,将MW124的值自增1,再与LT中的88比较,结果仍为小于,以此循环,直到MW124的值为88时,LT的OUT为0,停止使能ADD指令,因此MW124的值最终为88;
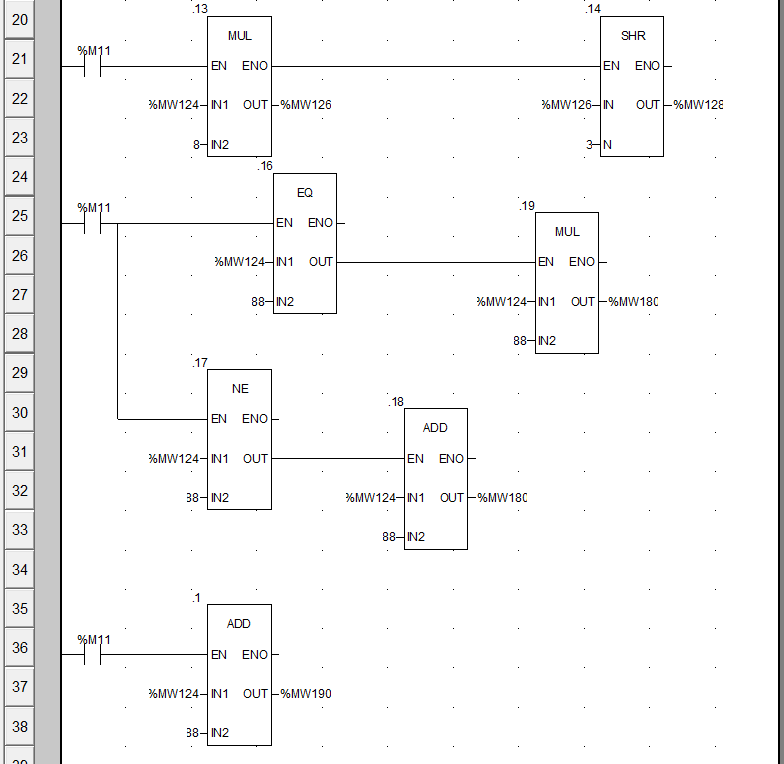
在第21行,使用MUL(Multiplication)指令,将MW124的值乘8,得到704存储在MW126中;再使用SHR(Shift right)向右移位指令,将MW126的值右移3位,得到88,存储在MW128中;
在第26行,使用EQ(Equal to)指令判断MW124的值与88是否相等,并使用结果使能MUL指令,将MW124乘88,存储在MW180中;
在第31行,使用NE(Not equal to)指令判断MW124的值与88是否不相等,并使用结果使能MUL指令,将MW124乘88,存储在MW180中;综上因为MW124只有等于88和不等于88两种情况,因此26和31行的效果实际为将MW124乘88,由于MW124最终为88,则MW180的值最终为7744;
在第36行,使用ADD指令,将MW124的值加上88得到MW190,最终为176;

在第42行,使用GT(Greater than)指令比较MW180是否大于MW190,并使用结果使能DIV命令,使得MW180除以88得到MW200的值;
在第46行,使用EQ命令判断MW180是否等于MW190,并使用结果使能SUB命令,使得MW180减去2得到MW200的值;
在第51行,使用LT命令判断MW180是否小于MW190,并使用结果使能SUB命令,使得MW190减去MW180的值为MW200的值;
综上所述,MW124的值在自增中最后停止在88,此时MW180的值为7744,MW190的值为176,在42、46、51行的条件判断中,只有第一种情况满足,最终MW200的值为MW180除以88,即为88。
下面进行程序仿真操作,在PLC选项卡中选择“设置地址”,设置仿真器的地址为127.0.0.1,采用TCPIP的方式连接;然后选择“连接”。上传项目结束后,点击运行,程序开始仿真。
设置M10的值为1,此时M11的值被设置为1,程序开始正常运行。可以看到MW102的位置已经赋值88。
此时查看MW200的值,为88,并且条件判断中只有第42行对应的指令输出为通路,表明上述分析正确。程序被篡改后MW200的值错误输出为88。