网络内容安全 | 笔记
第一章 网络信息内容获取技术
一、网络信息内容获取模型
1.1 网络信息内容获取模型
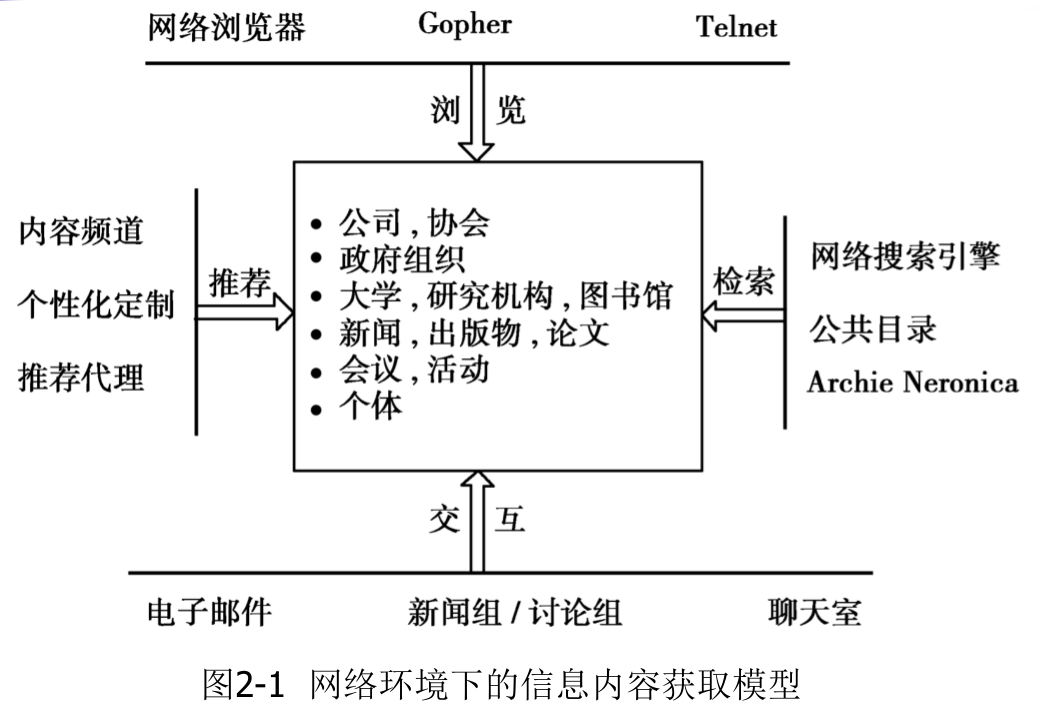
1.2 网络媒体信息获取原理
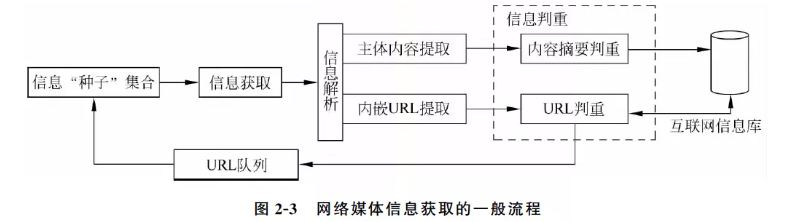
网络媒体信息获取的分类
- 全网信息获取
- 定点信息获取
- 基于主题的信息获取和元搜索
1.3 网络通信信息获取原理
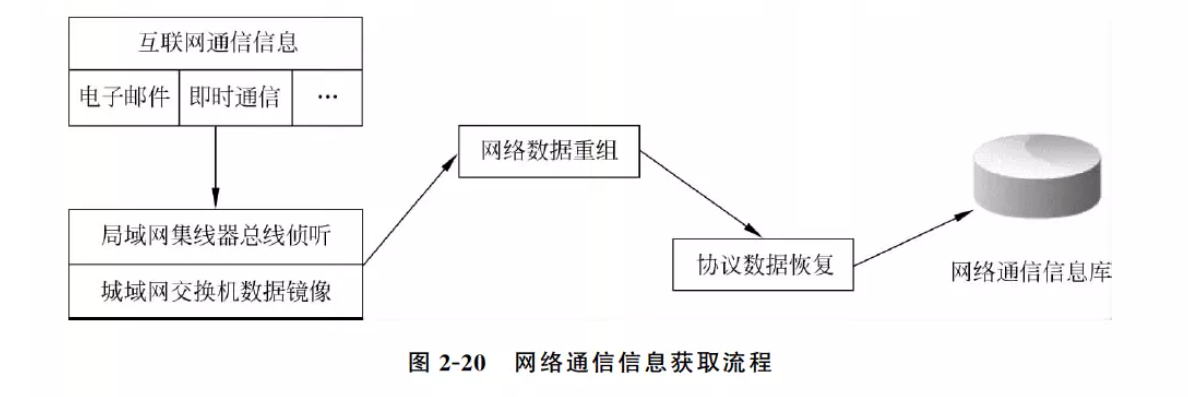
二、搜索引擎技术
中文搜索引擎的关键技术:
- 网页内容分析
- 网页索引
- 查询解析
- 相关性计算
2.1 网上采集算法(爬虫)
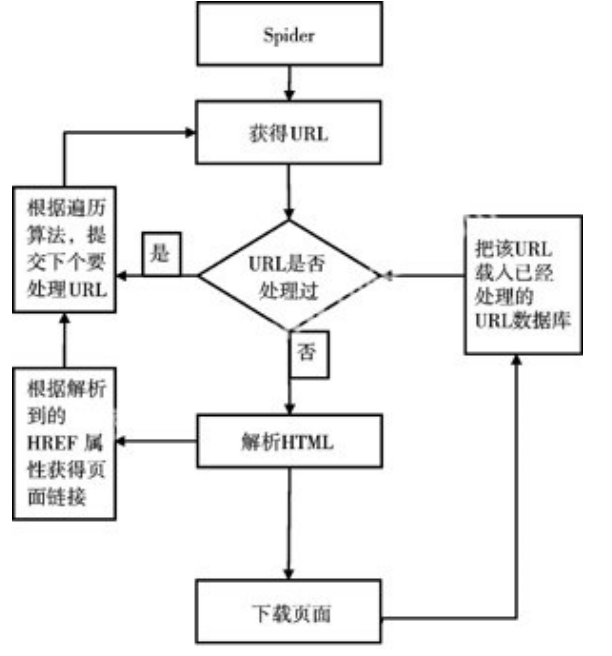
按照系统结构和实现技术,大致可以分为以下几种类型:
- 通用网络爬虫(General Purpose Web Crawler)
- 聚焦网络爬虫(Focused Web Crawler)
- 增量式网络爬虫(Incremental Web Crawler)
- 深层网络爬虫(Deep Web Crawler)
爬虫过程主要分为一下四步:
- 初始URL集合
- 信息获取:根据来自网络地址集合或URL队列中的每条网络地址信息,确定获取内容所采用的信息发布协议。基于特定协议的网络交互机制,向信息发布网站请求所需内容。
- 信息解析:从网络响应信息相应位置提取发布信息的主体内容(信息关键字段包括:信息来源、信息标题、信息失效时间、信息最近修改时间等等)。
- 信息判重:主要基于网络媒体信息URL与内容摘要两大元素,实现信息采集/存储的与否判断。
爬虫URL抓取策略:
- 深度优先遍历策略
- 宽度优先遍历策略
- 反向链接数策略:反向链接数表示的是一个网页的内容受到其他人的推荐的程度/引用的次数。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
- Partial PageRank策略:对于于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面
- OPIC策略:在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
- 大站优先策略:对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。
2.2 排级算法
网页排级是对搜索结果的分析,使那些更具“重要性”的网页在搜索结果中的排名获得提升,从而提高搜索结果的相关性和质量。
1. PageRank
原理:民主表决
核心思想: 在互联网上,如果一个网页被很多其它网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。.
假设互联网是一个有向图,在其基础上定义随机游走模型,即一阶马尔可夫链,表示网页浏览者在互联网上随机浏览网页的过程。假设浏览者在每个网页依照连接出去的超链接以等概率跳转到下一个网页,并在网上持续不断进行这样的随机跳转,这个过程形成一阶马尔可夫链。PageRank表示这个马尔可夫链的平稳分布。每个网页的PageRank值就是平稳概率。
对于网页关系:
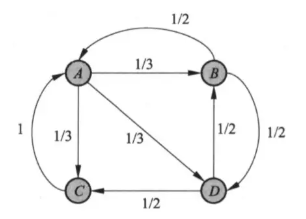
有转移矩阵(随机游走模型,即一阶马尔可夫链)为:
给定一个包含
平稳分布
PageRank 的一般定义:
计算方法:
为每个页面赋相同的初值,计算每个页面的PR值,应满足所有页面PR值和为1。若和不为1,则按比例对所有结果进行缩小,使得其和为1.
网页数量过大问题的解决方法:
- 稀疏矩阵
- MapReduce
优点:
- 直接高效
- 主题集中
缺点:
- 完全忽略网页内容,干扰挖掘结果
- 结果范围窄
- 影响因子与网页获取数量缺乏科学性
2. HITS
在HITS算法中,每个页面被赋予两个属性:Hub属性和Authority属性。具有上述两种属性的网页分为两种:Hub页面和Authority页面。
Hub(枢纽)页面:类似于一个分类器,其为包含了很多指向高质量Authority页面链接的网页。例如,hao123首页汇集了全网优质网址,故可以认为其是一个典型的高质量Hub网页;
Authority(权威)页面:类似于一个聚类器,其为与某个领域或者某个话题相关的高质量网页。例如,京东首页、淘宝首页等,都是与网络购物领域相关的高质量网页。
枢纽值(Hub Scores)页面上所有导出链接指向页面的权威值之和。
权威值(Authority Scores)所有导入链接所在的页面的枢纽值之和。
HITS算法的目的即是通过一定的技术手段,在海量网页中找到与用户查询主题相关的高质量Authority页面和Hub页面,尤其是Authority页面,因为这些页面代表了能够满足用户查询的高质量内容,搜索引擎以此作为搜索结果返回给用户。
HITS算法基于两个重要的假设:
- 一个高质量的Authority页面会被很多高质量的Hub页面所指向;
- 一个高质量的Hub页面会指向很多高质量的Authority页面。
算法步骤:
- 接受一个用户查询的请求。
- 将查询提交给某个现有的搜索引擎,并在返回的搜索结果中,提取排名在前n(n一般取200左右)的网页,得到一组与用户查询高度相关的初始网页集合,这个集合被称作为 root set(即根集)
- 在根集的基础上,将与根集内网页有直接链接指向关系的网页(每个网页取d个,d一般取50左右)扩充进来形成base set(即扩展集)。
- 计算最终集中所有页面的Hub值和Authority值。
- 依据Authority值对页面进行排序,取值较高的前若干位返回作为用户查询结果的响应。
缺点:
- 计算效率低,实时性差
- “主题漂移”
- 易被作弊者操纵结果:作弊者可以建立一个很好的Hub页面,再将这个网页链接指向作弊网页,可以提升作弊网页的Authority得分
- 结构不稳定:在原有的“扩充网页集合”内,如果添加删除个别网页或者改变少数链接关系,则HITS算法的排名结果就会有非常大的改变。
优点:
- 知识范围扩大。
- 搜索时部分地考虑了页面内容,挖掘结果科学性大大增强。
3. 比较
HITS算法是与用户输入的查询请求密切相关的,而PageRank与查询请求无关。所以,HITS算法可以单独作为相似性计算评价标准,而PageRank必须结合内容相似性计算才可以用来对网页相关性进行评价。
HITS算法因为与用户查询密切相关,所以必须在接收到用户查询后实时进行计算,计算效率较低;而PageRank则可以在爬虫抓取完成后离线计算,在线直接使用计算结果,计算效率较高。
HITS算法的计算对象数量较少,只需计算扩展集合内网页之间的链接关系;而PageRank是全局性算法,对所有互联网页面节点进行处理。
从两者的计算效率和处理对象集合大小来比较,PageRank更适合部署在服务器端,而HITS算法更适合部署在客户端。
HITS算法存在主题泛化问题,所以更适合处理具体化的用户查询;而PageRank在处理宽泛的用户查询时更有优势。
2.3 搜索引擎与垃圾信息关系
搜索引擎优化(Search Engine Optimization):利用工具或其他手段,使目标网站符合搜索引擎的搜索规则,从而获得较好的排名。
SEO分为两类:
- 优化网站内容,提升网页质量
- 构造垃圾信息
垃圾信息制造手段包括:
- 提高排名(Boosting)技术
- 关键字垃圾(term spamming)
- 链接垃圾(link spamming)
- 隐藏(Hiding)技术
- 对所使用的Boosting技术进行隐藏,尽量不让用户和网络采集器发现
- 主要技术包括内容隐藏(content hiding)、伪装(cloaking)和重定向(redirection)
如何提高PR:
- 提升网页质量
- 登录搜索引擎和分类目录;以及友情链接,如果能获得来自PR值不低于4并与你的主题相关或互补的网站的友情链接,且很少导出链接,那样效果更好
- 写一些高质量的软文,发布到大型网站,如果得到大家的认可,你的网址会被无数的网站转载
- 搜索引擎收录一个网站的页面数量,如果收录的比例越高,对提高PR值越有利
- 把所有页面都提交给Google
- 制作一个网站地图/导航,包含所有要添加的网站,然后提交网站地图
三、数据挖掘技术
从大量非结构化、异构的Web信息资源中发现兴趣性(interestingness)的知识,包括概念、模式、规则、规律、约束及可视化等形式的非平凡过程.
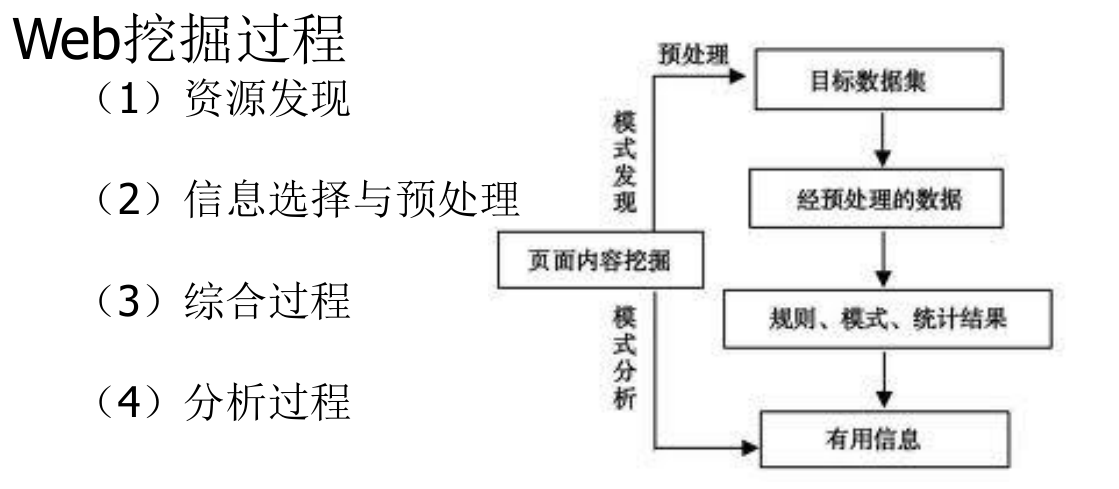
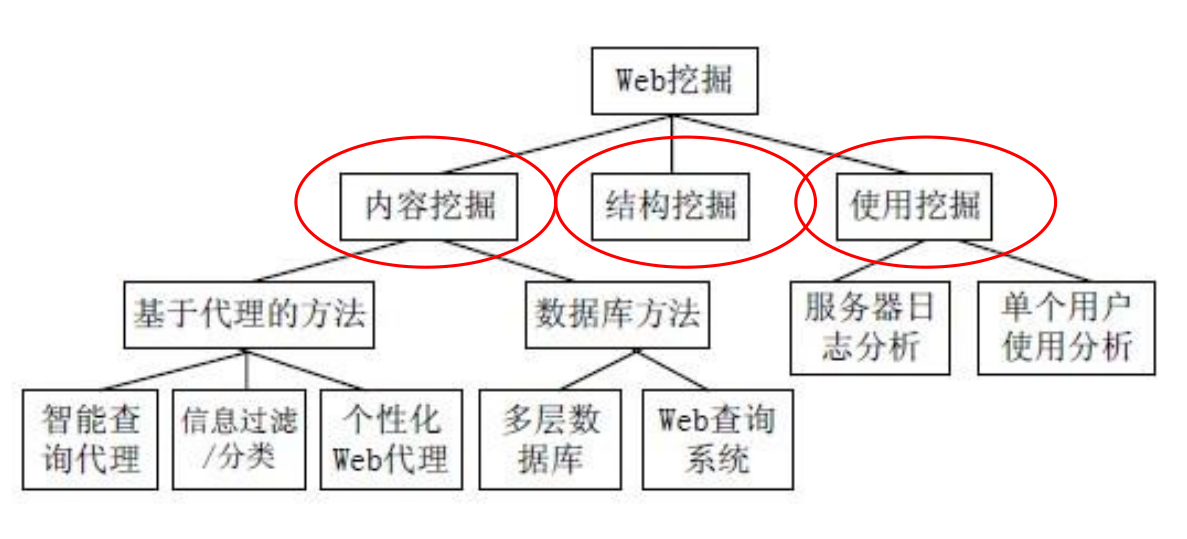
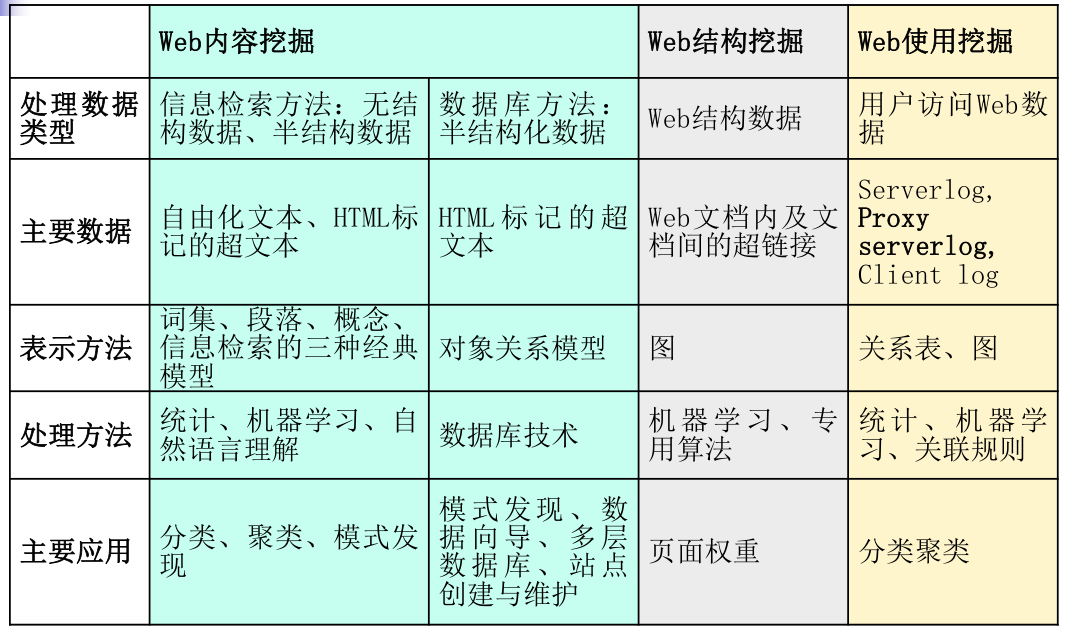
四、信息推荐技术
信息推荐算法:
- 基于内容推荐:根据用户已选择的对象,推荐其他类似属性的对象作为推荐。
- 协同过滤推荐:推荐相似用户所选择的对象
- 启发式方法:使用与新用户c相似的用户c’对一个对象的评价来预测s对新用户c的效用,进而判断是否推荐s给c。
- 基于模型的方法:利用用户c对众多对象的评分来学习一个c的模型,然后使用概率方法对新的对象s的推荐效用进行预测。
- 组合推荐
- 后融合组合推荐:融合两种或两种以上的推荐方法各自产生的推荐结果,判断使用其中的哪个推荐结果更好。属于结果层次上的融合
- 中融合组合推荐:以一种推荐方法为框架,融合另一种推荐方法。
- 前融合组合推荐:直接融合各种推荐方法。
五、信息还原技术
- 电脑还原技术
- 软件还原
- 硬件还原
- 网页还原技术
- 数据包捕获技术:网络数据包的捕获技术采用的网卡接收方式为混杂方式
- 协议还原技术
- 网页内容还原技术
- 多媒体信息还原技术.
六、课后题:
1. 各技术详细介绍
- 交互(Interaction): 是指人与计算机或其他设备之间的通信和数据交换。在软件设计中,良好的交互设计可以提高用户体验和效率。
- 信息浏览(Information Browsing): 指用户在互联网或内部系统上查找和浏览信息的过程。有效的信息浏览依赖于用户界面设计和搜索算法的优化。
- GYM: 通常指代互联网领域的三大巨头:谷歌(Google)、雅虎(Yahoo)、微软(Microsoft)。这些公司在搜索引擎、在线服务和软件开发等多个方面具有显著影响。
- URL(Uniform Resource Locator): 是一种网络资源的地址格式,用于在互联网上定位和访问网页、图片、视频等资源。
- Crawler(网络爬虫): 是一种自动访问网页并从中提取信息的程序,常用于搜索引擎索引、数据分析和网络内容监控。
- Sniffer(网络嗅探器): 是一种监测和分析网络流量的工具,用于网络安全、故障诊断和网络性能分析。
- Promiscuous(混杂模式): 是指网络设备(如网卡)接收并处理经过其网络接口的所有数据包,而不仅是发往该设备的数据包。这在网络监控和分析中很有用。
- Web挖掘(Web Mining): 指从网络数据(如网页内容、用户行为数据)中提取有用信息和模式的技术,可用于市场分析、搜索引擎优化等领域。
- SEO(Search Engine Optimization,搜索引擎优化): 指通过优化网站结构和内容,提高网站在搜索引擎中的排名和可见性的技术。
- 数据挖掘(Data Mining): 是从大量数据集中通过算法分析提取有价值信息和隐藏模式的过程,广泛应用于商业、科研等领域。
2. 信息获取技术分类及详细说明
信息获取技术可以分为以下几个主要类别:
- 数据采集技术:包括网络爬虫、API调用等,用于从互联网或其他数据源收集信息。
- 数据处理技术:涉及数据清洗、数据转换等,用于提高数据质量和便于进一步分析。
- 信息检索技术:包括搜索引擎技术、数据库查询等,用于从大量数据中查找特定信息。
- 数据分析技术:如数据挖掘、统计分析等,用于从数据中提取洞见和知识。
- 用户界面技术:涉及交互设计、信息可视化等,用于改善用户获取和处理信息的体验。
3. 信息内容获取模型详细内容
信息内容获取模型通常包含以下步骤:
- 需求分析:确定用户或系统需要什么样的信息,包括信息的类型、深度和用途。
- 信息源定位:识别和选择合适的信息源,如网络、数据库或其他数据存储。
- 信息获取:实际从信息源中获取信息,可能通过搜索、订阅、数据采集等方式进行。
- 信息处理:对获取的信息进行加工和整理,包括过滤无关信息、数据格式转换等。
- 信息存储:将处理后的信息储存于数据库或其他存储媒介,以便后续使用。
- 信息展示和传递:将信息以合适的方式呈现给用户,可能包括图表、报告或交互界面等。
4. PageRank核心原理及排名过程
PageRank是基于网页之间链接关系的一种算法,用于衡量网页的重要性。其核心原理和排名过程包括:
- 链接投票:一个网页链接到另一个网页,被视为对后者的“投票”或推荐。
- 重要性传递:重要的网页链接到的网页也被认为更重要。
- 排名计算:通过迭代计算所有网页的PageRank值。每个网页的PageRank值是所有链接到它的网页的PageRank值的总和,按链接数量和质量加权。
- 迭代更新:这个过程反复进行多次,直到所有网页的PageRank值达到稳定。
5. 信息还原技术的各方面
信息还原技术主要包括:
- 数据恢复:从损坏、格式化或者删除的存储设备中恢复数据。
- 错误检测与纠正:利用算法检测数据传输或存储过程中的错误,并进行修正。
- 信息重构:在部分数据缺失或损坏的情况下,尝试基于现有数据和模式重建原始信息。
- 备份和恢复策略:定期备份重要数据,并在数据损坏时进行恢复。
- 文件系统修复:修复损坏的文件系统,恢复文件系统的结构和存储的数据。
第二章 文本挖掘基础:文本预处理
一、文本挖掘的背景
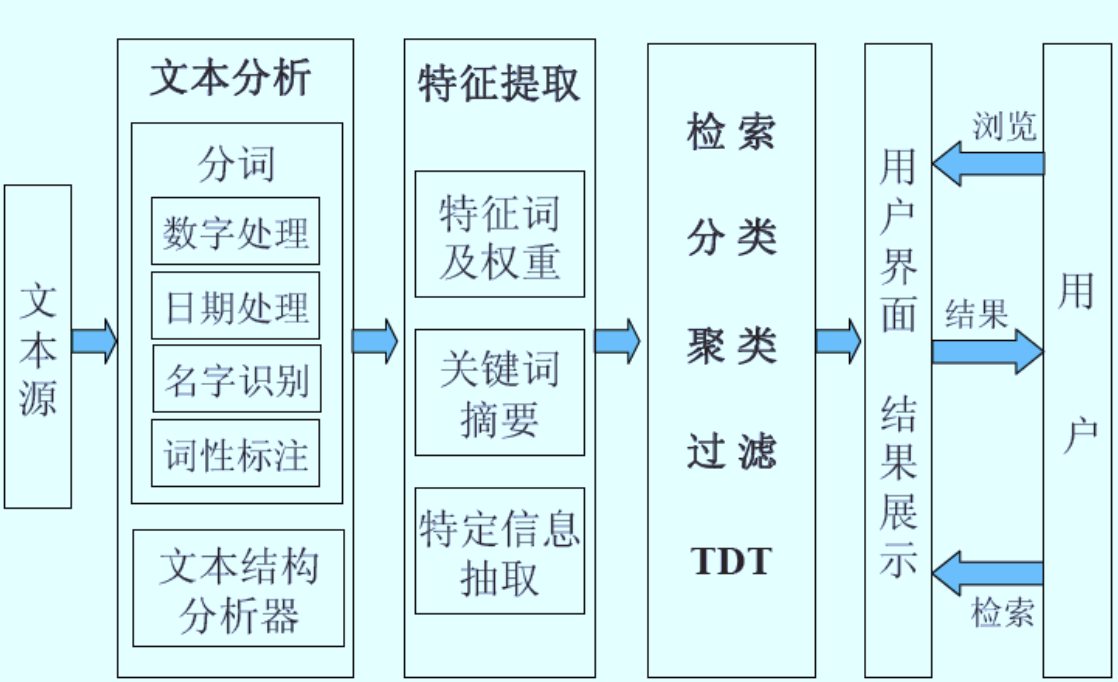
二、分词
2.1 数字的识别
使用正则表达式识别(有限状态自动机)
2.2 词语标记(Tokenization)算法
算法过程:
- 指针从左到右扫描字符char,存储在W[i]中,i++
- 如果当前指针位置char是分隔符 并且W不是空格,则将分隔符之前的内容输出为一个单词,并从句子中删除整个单词,并清空W 如果W是空格,则清空W,并从句子中删除这个空白字符
2.3 词性还原(Lemmatization)算法:
屈折型语言的词的变化形式:
- 屈折变化:词性不变,但形式发生变化,例如动词的过去式、单三等
- 派生变化:词性变化,一个单词从另外一个不同类单词或词干衍生过来。
- 符合变化:两个或更多个单词以一定的方式组合成一个新的单词。
需要:
- 词典(Dict)
- 前缀表(PrefixList)
- 后缀表(SuffixList)
- 有关屈折词尾变形的规则(Rules)
算法过程:
待分析的词语W,单词字符数为d,i=1
- 在词典(Dict)中查找单词W,如果找到,直接输出
- 如果i<=(d/2)
- 从W中取出i个尾字符串,W成为两部分W1+W2
- 到后缀表(SuffixList)中查找W2,如果查到,调用规则,对W1进行处理,得到W1'
- 到Dict中查找W1',如果找到,输出W1' 和 W2
- i=i+1
2.4 汉语分词
汉语分词面临的问题:
- 重叠词、离合词(担心:担什么心)、词缀
- 汉语的切分歧义
- 交集型歧义(交叉型歧义):如果字串abc既可切分为ab/c,又可切分为a/bc。 有意见: 我 对 他 /有/意见。 总统/有意/见他。
- 组合型歧义(覆盖型歧义):若ab为词,而a和b在句子中又可分别单独成词。 – 马上:我/马上/就 来。 他/从/马/上/下来。
- 混合型歧义
- 汉语的未登录词(词库中没收录的词语)
1. 正向最大匹配法(MM)
正向即从左往右取词,取词最大长度为词典中长词的长度,每次右边减一个字,直到词典中存在或剩下1个单字。
举例:
sentence = '我们在野生动物园玩'
user_dict = ['我们', '生动', '野生', '动物园', '野生动物园', '物','玩']
词典最大长度 max_len = 5
匹配过程:
最大长度为5,从头取出5个字“我们在野生”,然后进行扫描
第1次:“我们在野生”,扫描词典,无 第2次:“我们在野”,扫描词典,无 第3次:“我们在”,扫描词典,无 第4次:“我们”,扫描词典,有
扫描中止,输出第1个词为“我们”,去除第1个词后,开始第2轮扫描
取出“在野生动物”进行扫描
第1次:“在野生动物”,扫描词典,无 第2次:“在野生动”,扫描词典,无 第3次:“在野生”,扫描词典,无 第4次:“在野”,扫描词典,无 第5次:“在”,只剩下一个字,输出
扫描中止,输出一个字为“在”,去除第2个词后,开始第3轮扫描
取出”野生动物园“,在字典中,输出
取出”玩“,只有一个字,输出
结果为:“我们/在/野生动物园/玩”
如果词典中有词语”在野“,则分词结果为:“我们/在野/生动/物/园/玩”
2. 逆向最大匹配法(RMM)
逆向即从后往前取词,其他逻辑和正向相同。
例如上个例子中,先取出”生动物园玩“,从前往后删除字,“动物园玩”、“物园玩”、“园玩”、“玩”,取出“玩”
3. 双向最大匹配
依次采用正向最大匹配和反向最大匹配
- 如果结果一致则输出
- 如果结果不一致,则采用其他方法排歧
正向最大匹配法,最终切分结果为:“我们/在野/生动/物/园/玩”,其中单字字典词为2,非词典词为1。 逆向最大匹配法,最终切分结果为:“我们/在/野生动物园/玩”,其中,单字字典词为2,非词典词为0。 非字典词:正向(1)>逆向(0)(越少越好) 单字字典词:正向(2)=逆向(2)(越少越好) 总词数:正向(6)>逆向(4)(越少越好) 因此最终输出为逆向结果。
最大匹配法分词的问题:
最大词长的确定
词长过短,长词会被切错(“中华人民共和国”) 词长过长,效率就比较低
掩盖了分词歧义问题,没有处理
能发现部分交集型歧义,无法发现组合型歧义
对于某些交集型歧义,可以增加回溯机制来改进最大匹配法,对不在字典的单字进行进一步处理
4. 最大概率法分词
一个待切分的汉字串可能包含多种分词结果,将其中概率最大的作为该字串的分词结果。
例句:“有意见分歧”
对候选词wi的累计概率:
左邻词:“意见”和“见”都是“分歧”的左邻词
最佳左邻词:某个候选词有若干个左邻词,其中累计概率最大的为最佳左邻词。
算法过程:
- 对一个待分词句子,从左到右取出所有候选词
- 查出每个候选词的概率,并记录每个候选词的全部左邻词
- 计算每个候选词的累计概率,得到最佳左邻词
- 到达尾词w_n,并且w_n的累计概率最大,则w_n是终点词
- 从终点词开始向前,输出每个词的最佳左邻词,则为分词结果
缺点:
- 并不能解决所有的交集型歧义问题
- 无法解决组合型歧义问题
三、文档模型
1. 布尔模型
建立在经典的集合论和布尔代数的基础上,每个词在一篇文档中是否出现,对应权值为0或1
文档检索→布尔逻辑运算
优点:简单、易理解、简洁的形式化。
缺点:准确匹配,信息需求的能力表达不足。
2. 词袋模型
在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。
Wikipedia上给出了如下例子:
John likes to watch movies. Mary likes too.
John also likes to watch football games.
根据上述两句话中出现的单词, 我们能构建出一个字典 (dictionary):
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10}
该字典中包含10个单词, 每个单词有唯一索引, 注意它们的顺序和出现在句子中的顺序没有关联. 根据这个字典, 我们能将上述两句话重新表达为下述两个向量:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
这两个向量共包含10个元素, 其中第i个元素表示字典中第i个单词在句子中出现的次数. 因此BoW模型可认为是一种统计直方图 (histogram). 在文本检索和处理应用中, 可以通过该模型很方便的计算词频.
词袋模型中,向量中可以使用1/0值表示是否出现,可以使用词频,也可以填入TF-IDF值。
3. n-gram模型
?(ngram不能向量化的表示一个文章)
4. TF-IDF算法
词频(TF)= 某词在文章中出现的总次数 / 文章的总词数
逆文档频率(IDF)= log(语料库的文档总数 / (包含该词的文档数 + 1))
TF-IDF = TF × IDF
四、文档相似度计算
4.1 基于概率模型的相关度
BM25算法
4.2 基于向量空间模型的相关度
SVM
4.3 基于向量内积的相关度
1. 欧式距离
2. 向量内积相似度
3. 余弦相似度
4. Jaccard相似度
4.4 基于文本序列的相关度
- 序列比较
- 海明距离
- 编辑距离
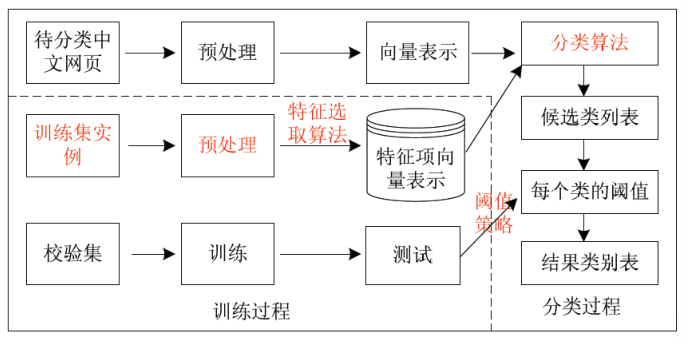
第三章 文本分类
文本分类的基本步骤:
一、评价指标

准确率:预测正确的样本总数 ÷ 总样本数
精确率(Precision):预测正确的样本数 ÷ 预测出来的样本数,即
召回率(Recall):预测正确的样本数 ÷ 标志的样本数(即事实上正确的样本数),即
F1:
宏平均:把每个类别都当作正类计算一下precision,recall,f1然后求和求平均
微平均:
二、特征选择
2.1 文档频率(DF: Document Frequency)
TF-IDF算法
TF-IDF算法的主要思想是:如果某个词或短语在某一篇文章中的出现频率TF越高,而且在其它文章中很少出现,那么认为此词或者短语具有很好的类别区分能力,适合用来分类。

在统计之前必须要过滤掉文档中的停用词。当然TF-IDF的精确度有时候可能不太高,它仍有不足之处,单纯地认为文本频率越小的单词就越重要,而文本频率越大的单词就越无用,显然这并不完全正确。
计算出文档中每个词的TF-IDF的值,然后按照降序排列,取前面的几个词作为特征属性。这里由于只取前K大的,有比较优秀的O(n)算法。
在文本分类中单纯地用TF-IDF来判断一个特征属性是否具有区分度是不够的,原因主要有如下两个:
- 没有考虑特征词在类间的分布 如果一个特征词在各个类之间分布都比较均匀,那么这样的词对分类没有任何贡献;而如果一个特征词集中分布在某个类中,在其它类中都出现但是出现的频率很小很小,那么这个词能很好地代表这个类的特征属性,但是TF-IDF不能很好地区别这两种情况。
- 没有考虑特征词在类内部文档中的分布 在类内部文档中,如果特征词均匀分布在其中,那么这个特征词能够很好地代表这个类的特征,如果只在几篇文档中出现,那么不能够代表这个类的特征。
2.2 信息增益(IG: Information Gain)?
条件熵:在某一条件下,随机变量的不确定性。
信息增益:在某一条件下,随机变量不确定性减少的程度。
在信息增益中,重要的衡量标准就是看这个特征能够为分类系统带来多少信息,带来的信息越多,那么该特征就越重要。通过信息增益选择的特征属性只能考察一个特征对整个系统的贡献,而不能具体到某个类别上,这就使得它只能做全局特征选择,即所有的类使用相同的特征集合。
2.3 互信息(MI: Mutual Information)
互信息是事件A和事件B发生相关联而提供的信息量,在处理分类问题提取特征的时候就可以用互信息来衡量某个特征和特定类别的相关性,如果信息量越大,那么特征和这个类别的相关性越大。反之也是成立的。

特点:
- MI(t,c) 的值越大,t对C的区分能力越强
- 同一个类中,相对稀有的词t会得到较大的值
- 一个词如果频次不够多,但是又主要出现在某个类别里,那么就会出现较高的互信息,从而给筛选带来噪音。 所以为了避免出现这种情况可以采用先对词按照词频排序,然后按照互信息大小进行排序,然后再选择自己想要的词,这样就能比较好的解决这个问题。
2.4 卡方(CHI)
卡方检验是数理统计中一种常用的检验两个变量是否独立的方法。在卡方检验中使用特征与类别间的关联性来进行量化,关联性越强,特征属性得分就越高,该特征越应该被保留。
卡方检验最基本的思想是观察实际值和理论值的偏差来确定理论的正确性。通常先假设两个变量确实是独立的,然后观察实际值与理论值的偏差程度,如果偏差足够小,那么就认为这两个变量确实是独立的,否则偏差很大,那么就认为这两个变量是相关的。
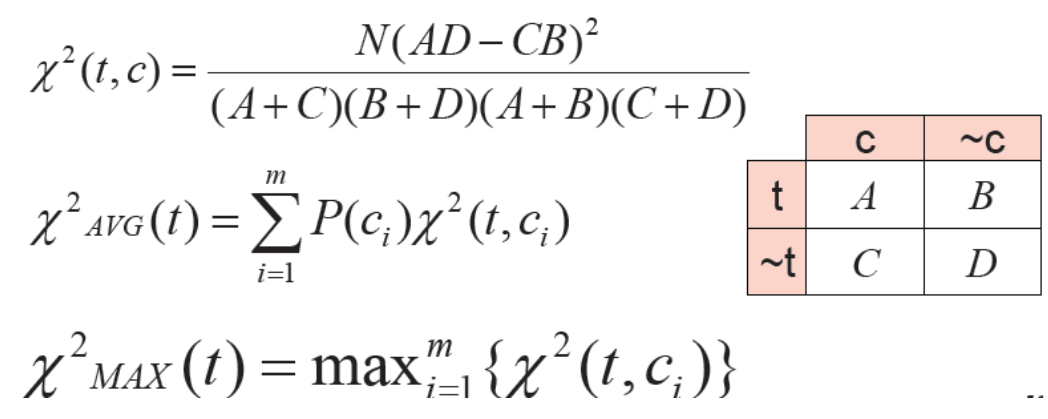
三、分类算法
3.1 KNN分类
输入没有标签的新数据后,将新数据与样本集中数据进行比较,然后算法提取样本集中最相似数据(最近邻)的分类标签。
一般来说,只选择样本数据集中前N个最相似的数据。K一般不大于20,最后,选择k个中出现次数最多的分类,作为新数据的分类。
距离计算:方式有多种,比如常见的曼哈顿距离计算、欧式距离计算等等。
欧式距离计算公式:
K值的选择:通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的 K 值开始,不断增加 K 的值,然后计算验证集合的方差,最终找到一个比较合适的 K 值。
优点:
- 简单、有效
- 重新训练方便
- 计算时间和空间的规模与训练集规模成线性关系
- KNN是一种非参的(不会对数据做出任何的假设)、惰性的(没有明确的训练数据的过程)算法模型。
缺点:
- 对内存要求较高,因为该算法存储了所有训练数据。
- 预测阶段可能很慢。
- 对不相关的功能和数据规模敏感。
3.2 贝叶斯分类
贝叶斯公式:
3.3 SVM分类
1. SVM介绍
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
分类:
- 线性可分支持向量机:硬间隔最大化
- 线性支持向量机:训练数据近似线性可分时,通过软间隔最大化
- 非线性支持向量机:当训练数据线性不可分时,通过使用核技巧(kernel trick)及软间隔最大化
2. SVM算法原理
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。
参考:【机器学习】支持向量机 SVM - 知乎 (zhihu.com)
(1)间隔最大化
超平面可表示为:
对于每个数据:
为了最大化这个距离
因此得到最优化问题:
得到带有约束条件的问题:
则原来的
对
,约束条件 不起作用,且 ,约束条件 起作用,且
则综合可得:
由此方程组转换为,得到不等式约束优化优化问题的
KKT条件:
那么最优化问题转换为:
拉格朗日函数对偶性,将最小和最大的位置交换一下,得到:
3. SVM求解过程
主要问题是:
构造拉格朗日函数:
利用强对偶性转化:
对参数 w 和 b 求偏导数: 得到: 带回函数中,得到: 即: 得到问题:
这是一个二次规划问题,问题规模正比于训练样本数,我们常用 SMO(Sequential Minimal Optimization) 算法求解。通过 SMO 求得最优解 。 求偏导数时得到:
由上式可求得 w。 并且所有
对应的点都是支持向量,我们可以随便找个支持向量,然后带入: ,求出 b 即可: w 和 b 都求出来了,我们就能构造出最大分割超平面:
分类决策函数:
其中sign为阶跃函数:
4. SVM算法过程(PPT)
特征空间上的训练集:
- 函数间隔: 给定一个训练样本
x是特征,y是结果标签,i表示第i个样本。定义函数间隔为: 。 由于是一个训练样本,那么为了使函数间隔最远(更大的信息确定该样本是正例还是反例),所以,当yi = 1时,我们希望w ∗ xi + b能够非常大,反之是非常小。因此函数间隔代表了我们认为特征是正例还是反例的确信度。 函数间隔如果同时扩大w和b的话,点之间的距离会扩大,但是超平面没有变化。 - 几何间隔:
,表示了一个训练样本到超平面的距离。所以SVM实际的目的时找到函数间隔最小的那对样本,并且要让它的几何间隔最大。 - 两者的关系:
最大间隔分类的超平面,就是要找到:
在线性可分情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量(support vector);支持向量是使约束条件式等号成立的点。
构造拉格朗日函数:
先求对w,b的极小值,对w,b分别求偏导,令等于0,得到:
带入原式中,得到: 对${w,b}L(w,b,)
-{w,b}L(w,b,) $求极小,得到表达式: 定理:若
是上述式子的解,则存在 ,可以求得原始问题的解(偏导第一个式子,和最优化问题的取等条件): 因此,分离超平面可以写成:





5. 软间隔最大化





6. 非线性支持向量机与核函数
非线性问题往往不好求解,所以希望能用解线性分类间题的方法解决这个问题。
采取的方法是进行一个非线性变换,将非线性问题变换为线性问题,通过解变换后的线性问题的方法求解原来的非线性问题。
原空间:
新空间:
分隔平面:
核技巧:通过一个非线性变换将输入空间(欧氏空间或离散集合)对应于一个特征空间(希尔伯特空间),使得在输入空间中的超曲面模型对应于特征空间中的超平面模型(支持向量机)。分类问题的学习任务通过在特征空间中求解线性支持向量机就可以完成
核函数:设X是输入空间(欧氏空间R^n的子集或离散集合),又设H为特征空间(希尔伯特空间),如果存在一个从X到H的映射:

使用
常用核函数:
多项式核函数(Polynomial kernel function):
对应的支持向量机为P次多项式分类器 高斯核函数 (Gaussian Kernel Function)/ 径向核函数:
字符串核函数
7. 序列最小最优化算法 (SMO)
解如下凸二次规划的对偶问题:(变量是拉格朗日乘子αi,一个对应一个样本)
- 如果所有变量的解都满足此最优化问题的KKT条件,那么得到解
- 否则,选择两个变量,固定其它变量,针对这两个变量构建一个二次规划问题,称为子问题,可通过解析方法求解
- 子问题的两个变量:一个是违反KKT条件最严重的那个,另一个由约束条件自动确定:

第四章 文本挖掘:聚类
一、聚类方法概述
1.1 概述
聚类:聚类(clustering)也称为聚类分析,指将样本分到不同的组中使得同一组中的样本差异尽可能的小,而不同组中的样本差异尽可能的大。
聚类得到的不同的组称为簇(cluster)。
一个好的聚类方法将产生以下的聚类:
- 最大化类中的相似性
- 最小化类间的相似性
聚类和分类的区别:
- 聚类的样本不具有类别标号,是无监督学习,可以先聚类,再对有限的簇指定类别
- 分类的样本有类别标号,是有监督学习,需要高昂的代价标记训练样本
1.2 聚类分析中的数据类型
文本向量模型 / 数据矩阵(Data matrix,或称对象-属性结构)
用 p 个变量(也称为属性)来表现 n 个对象,这种数据结构是关系表的形式,或者看为 n×p 维( n 个对象*p 个属性)的矩阵。
相异度矩阵(dissimilarity matrix 或称对象-对象结构)
存储 n 个对象两两之间的近似性,表现形式是一个 n×n 维的矩阵。在这里 d(i,j)是对象 i 和对象 j 之间相异性的量化表示,通常它是一个非负的数值,当对象 i 和j 越相似,其值越接近 0;两个对象越不同,其值越大。既然 d(i,j) = d(j,i),而且 d(i,i)=0,我们可以得到如下的矩阵。
1.3 相异度计算
1. 区间标度变量
两个点:
欧几里得距离
两个元素在欧氏空间中的集合距离
曼哈顿距离
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
民科夫斯基距离
明氏距离是一组距离的定义,公式中其中p为一个变参数,当p=1时,就是曼哈顿距离;当p=2时,就是欧式距离;当p→∞时,就是切比雪夫距离。
余弦相似度
余弦度量的是两者的相似度,cosθ余弦值的取值范围[-1,1]。夹角余弦越大,表示两个向量的夹角越小,越相似;夹角余弦越小,表示两个向量之间的夹角越大,越不相似。
2. 二元变量
只有两个状态(0或1)的变量称为二元变量。二元变量分为对称的和非对称的两种。如果假设所有的二元变量有相同的权重,则可以得到一个两行两列(2*2)的条件表。

对于对称的二元变量,两个状态是等价值的,有相同的权重,例如性别中男性和女性,则相异度计算为:
对于不对称的二元变量,两个状态的权重不同,例如疾病的阳性和阴性,我们把重要的状态编码为1,次要的为0。此时两个都取1的匹配比两个都取0的匹配更有意义。
此时相异度计算为:
相似度计算为:(Jaccard系数)
3. 分类变量 / 标称变量
对二元变量进行拓展,属性的取值为多种,而不是只有1/0。相异度计算为:
4. 序数变量 / 顺序变量
对分类变量进行拓展,属性取值有若干种,并且这些状态可以依据某标准进行排序。
则计算相异度时,先将状态f替换为它的秩(它排序的序号1,2,3,...,M),然后将秩映射到[0,1]区间上,可以通过下面变换实现:
接下来就可以用区间标度变量中所描述的任意一组距离度量方法进行计算相异度。
5. 比例标度变量
属性的取值随时间呈指数增长趋势,例如:
计算相异度时可以:
- 直接当作区间标度变量处理,但是不好,比例尺度是非线性的。
- 把比例标度度量当做序数变量处理
- 对比例标度度量做对数变换:
6. 混合变量模型
相异度计算:
二、划分聚类方法
给定一个有n个对象的数据集,划分聚类技术将构造数据k个划分,每一个划分就代表一个簇。也就是说,它将数据划分为k个簇,而且这k个划分满足下列条件:
- 每一个簇至少包含一个对象。
- 每一个对象属于且仅属于一个簇。
2.1 聚类的差异
类内差异
类内差异度量了一个簇内部对象之间的相似性或紧密度。通常,我们希望簇内的对象越相似越好,这意味着在同一个簇中的对象应该彼此接近。
类内差异可以通过计算簇内对象之间的平均距离或方差来衡量。较小的类内差异值表示簇内的对象更相似,簇内更紧密。例如:
类间差异
类间差异度量了不同簇之间的分离性或差异性。它表示不同簇之间的对象应该尽可能地不相似,这有助于区分不同的簇。
类间差异可以通过计算不同簇之间的平均距离或方差来衡量。较大的类间差异值表示不同簇之间的对象更不相似,簇间更分离。例如:
聚类的总体质量可以定义为
和 的单调组合,例如
2.2 k-means 算法
K均值聚类(K-Means Clustering)是一种常用的划分聚类算法,它被用来将数据集分成不同的簇。这个算法的主要思想是将数据点划分为k个簇,每个簇的中心是该簇内所有数据点的均值。
算法基本步骤:
- 初始化:首先,选择要分成的簇数k。然后从数据集中随机选择k个点作为初始簇的中心点,这些点可以是数据集中的实际数据点或者随机生成的点。
- 分配数据点:对于每个数据点,计算它与每个簇中心的距离,通常使用欧氏距离或其他距离度量。将数据点分配给距离最近的簇中心,使得它属于该簇。
- 更新簇中心:对于每个簇,计算簇内所有数据点的均值,并将该均值作为新的簇中心。
- 重复步骤2和步骤3:重复执行分配数据点和更新簇中心的步骤,直到满足停止条件。常见的停止条件包括簇中心不再发生明显变化,或者指定的迭代次数已达到。
- 输出结果:算法结束后,每个数据点都被分配到一个簇中。这就是K均值聚类的最终结果。
优点:
- 简单且易于理解:K均值聚类是一个直观和易于理解的算法。它的基本原理是直观的,容易实现和解释,因此适用于初学者和非专业人士。
- 计算效率高:K均值聚类在大规模数据集上运行效率很高,因为它的时间复杂度通常是线性的,而且算法迭代次数通常较少。
- 适用于均匀分布的簇:当数据的簇是凸形的、球形的或近似球形的时候,K均值聚类的效果通常很好。
缺点:
- 需要定义平均值:在簇的平均值被定义的情况下才能使用,可能不适用于某些应用。
- 需要预先指定簇数k:在使用K均值聚类之前,需要预先知道要分成多少个簇。选择不合适的k值可能导致聚类结果不准确。有一些方法可以帮助估计合适的k值,但仍然需要主观决策。
- 假设簇是凸形的:K均值聚类假设簇是凸形的,对于非凸形的簇效果较差。
- 不适用于不均匀大小和形状的簇:如果簇的大小和形状差异很大,K均值聚类可能会产生不理想的结果。
- 对异常值敏感:K均值聚类对异常值(离群点)敏感,异常值可能会影响簇的中心位置,从而导致不正确的聚类结果。
k-中心点算法:
k-means算法对于孤立点是敏感的。为了解决这个问题,引入了k-中心点算法,该算法不采用簇中的平均值作为参照点,可以选用簇中位置最中心的对象,即中心点作为参照点。
2.3 PAM算法
PAM(Partitioning Around Medoids)算法是一种聚类算法,它是K均值聚类的一种改进版本,旨在解决K均值聚类对离群点和异常值敏感的问题。与K均值聚类不同,PAM算法使用数据点作为中心点,而不是数据的均值,这使得它对离群点更具鲁棒性。
k-medoids修正聚类中心的时候,是计算类簇中除开聚类中心的每点到其他所有点的聚类的最小值来优化新的聚类中心。正是这一差别使得k-mediod弥补了k-means算法的缺点:k-mediod对噪声和孤立点不敏感。
算法流程为:z
- 在总体n个样本点中任意选取k个点作为medoids
- 按照与medoids最近的原则,将剩余的n-k个点分配到当前最佳的medoids代表的类中(实现了初始的聚类)
- 对于第 i 个类中除对应medoids点外的所有其他点,按顺序计算当其为新的medoids时,准则函数的值,遍历所有可能,选取准则函数最小时对应的点作为新的medoids
- 重复2-3的过程,直到所有的medoids点不再发生变化或已达到设定的最大迭代次数
- 产出最终确定的k个类
准则函数: 最小化绝对误差:
另一种表达:
k‐均值迭代计算簇的中心的过程,在PAM算法中对应计算是否替代对象o′比原来的代表对象o能够具有更好的聚类结果,替换后对所有样本点进行重新计算各自代表样本的绝对误差标准。 若替换后,替换总代价小于0,即绝对误差标准减小,则说明替换后能够得到更好的聚类结果,若替换总代价大于0,则不能得到更好的聚类结果,原有代表对象不进行替换。 在替换过程中,尝试所有可能的替换情况,用其他对象迭代替换代表对象,直到聚类的质量不能再被提高为止。(贪心算法)
2.4 谱聚类算法
算法流程:

优点:
谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如K-Means很难做到。
由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。
缺点:
- 如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好。
- 聚类效果依赖于相似矩阵,不同的相似矩阵得到的最终聚类效果可能很不同。
三、层次聚类方法
基于层次的聚类方法是指对给定的数据进行层次分解,直到满足某种条件为止。该算法根据层次分解的顺序分为自底向上法和自顶向下法,即凝聚式层次聚类算法和分裂式层次聚类算法。
层次凝聚的代表是AGNES算法。层次分裂的代表是DIANA算法。
3.1 AGENS算法
AGNES 算法最初将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并。两个簇间的相似度有多种不同的计算方法。聚类的合并过程反复进行直到所有的对象最终满足簇数目。
算法步骤:
输入:包含n个对象的数据库。 输出:满足终止条件的若干个簇。
过程:
- 初始化:将每个对象当成一个初始簇。
- REPEAT
- 计算任意两个簇的距离,并找到最近的两个簇。
- 合并两个簇,生成新的簇的集合。
- UNTIL 终止条件得到满足。
两个簇之间的距离计算方式:
最小距离:两个簇中任意两个元素之间的距离的最小值
若采用最小距离的定义,簇与簇的合并方式称为单链接方法. 最大距离,距离的最大值
均值距离:两个簇中分别求的平均元素,然后做差
平均距离:两个簇中任意两个元素距离的平均值
终止条件:
- 设定一个最小距离阈值D,如果最相近的两个簇的距离已经超过D,则它们不需再合并,聚类终止。
- 限定簇的个数k,当得到的簇的个数已经达到k,则聚类终止。
缺点:
- 不可逆性:AGNES算法的一大缺点是一旦完成了两个簇的合并,就无法撤销这个操作。因此,如果在早期阶段错误地合并了两个不相似的簇,将会对最终的聚类结果产生较大的影响。这种不可逆性使得AGNES算法对于选择合适的距离度量和簇合并策略变得非常关键。
- 计算复杂性:AGNES算法在每次迭代中都需要计算所有对象两两之间的距离。这导致了算法的时间复杂度为O(n^2),其中n是数据点的数量。因此,当数据集很大时,计算距离矩阵和查找最近簇的成本会很高,因此该算法对于大规模数据集不太适用。
- 对初始簇数的敏感性:AGNES算法的性能也受到初始簇数的影响。不同的初始簇数和初始簇合并顺序可能会导致不同的最终聚类结果。因此,选择合适的初始条件对于获得理想的聚类结果非常关键。
- 不适用于非凸簇:与K均值聚类不同,AGNES算法假定簇可以是任意形状,这在某些情况下可以是一个优点。然而,对于非凸形状的簇,AGNES算法也可能产生不太理想的结果。
3.2 DIANA算法
DIANA(Divisive Analysis)算法是一种层次聚类算法,与AGNES(Agglomerative Nesting)算法相反,它是自顶向下的方法。DIANA算法的主要目标是将数据集分割成多个子集,每个子集表示一个簇,然后继续将这些子集进一步划分,直到每个簇包含一个数据点。
算法步骤:
输入:包含n个对象的数据库。 输出:满足终止条件的若干个簇。
过程:
- 初始化:将所有对象整个当成一个初始簇。
- REPEAT
- 在所有簇中挑出具有最大直径的簇C。
- 找出簇C中与其它点平均相异度最大的一个点p,并把p放入splinter group,剩余的放在old party中。
- REPEAT
- 在old party中选择一个点q。
- 计算点q到splinter group中的点的平均距离D1,计算点q到old party中的点的平均距离D2,保存D2-D1的值。
- 选择D1-D2取值最大的点q',如果D1-D2为正,把q'分配到splinter group中。
- UNTIL 没有新的old party的点被分配给splinter group。
- splinter group和old party为被选中的簇分裂成的两个簇,与其它簇一起组成新的簇集合。
- END.
简单的来说:
- 初始化,所有样本集中归为一个簇
- 在同一个簇中,计算任意两个样本之间的距离,找到 距离最远 的两个样本点a,b,将 a,b 作为两个簇的中心;
- 计算原来簇中剩余样本点距离 a,b 的距离,距离哪个中心近,分配到哪个簇中
- 重复步骤2、3 ……
- 直到,最远两簇距离不足阈值,或者簇的个数达到指定值,终止算法
3.3 Birch算法
BIRCH聚类算法原理 - 刘建平Pinard - 博客园 (cnblogs.com)
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)算法是一种层次聚类算法,旨在处理大规模数据集。BIRCH的主要优势在于它能够高效地处理大量数据并生成紧凑的数据摘要,同时保持聚类质量。
Birch算法是层次聚类算法之一,该算法引入了聚类特征和聚类特征树(Clustering Feature Tree)。
聚类特征树的每个节点都可以用它的聚类特征(CF)表示,形式为
CF树的参数:
- B:每个非叶子节点最多有B个分支
- L:每个叶子节点最多有L个CF 分支
- T:每个CF分支的直径不超过阈值T
算法可以分为两个步骤:
- BIRCH扫描数据库,建立一颗存放于内存的CF-树,它可以看作数据的多层压缩,试图保留数据内在的聚类结构。
- BIRCH采用某个(选定的)聚类算法对CF-树的叶子节点进行聚类,把稀疏的簇当做离群点删除,而把稠密的簇合并为更大的簇。
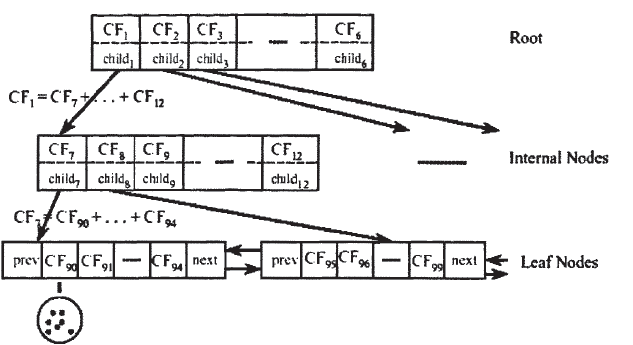
CF-树的构建流程:
- 从根节点开始:插入新样本时,从CF树的根节点开始搜索。
- 寻找最近的叶子节点和最近的CF节点:递归向下搜索,找到距离新样本最近的叶子节点以及叶子节点中最近的CF节点。这一步是为了确定新样本的插入位置。
- 检查CF节点的超球体半径是否满足阈值T:如果新样本被插入后,该CF节点对应的超球体半径(表示簇的范围)仍然满足小于阈值T,则说明可以将新样本加入到这个CF节点中,而无需进行分裂。在这种情况下,需要更新路径上所有的CF三元组以反映新样本的插入。
- 如果超球体半径不满足阈值T:如果插入新样本后,CF节点的超球体半径超过了阈值T,则需要进行分裂操作。
- 检查叶子节点的CF节点数量是否小于阈值L:如果当前叶子节点的CF节点数量小于阈值L,说明可以将新样本插入到当前叶子节点中。创建一个新的CF节点,将新样本放入该CF节点,然后将新的CF节点放入当前叶子节点。最后,需要更新路径上所有的CF三元组以反映新样本的插入。
- 如果CF节点数量已达到阈值L:如果当前叶子节点的CF节点数量已经达到阈值L,说明叶子节点已满,需要将叶子节点分裂为两个新的叶子节点。分裂过程如下:
- 选择旧叶子节点中超球体距离最远的两个CF元组,这两个CF元组将成为两个新叶子节点的第一个CF节点。
- 将其他CF元组和新样本元组按照距离远近的原则放入对应的新叶子节点。
- 然后,依次向上检查父节点是否也需要分裂,如果需要分裂,则按照与叶子节点相同的方式进行分裂。
- 结束插入操作:插入完成后,CF树的结构和数据摘要已更新,插入操作结束。
BIRCH算法主要流程
- 将所有的样本依次读入,在内存中建立一颗CF Tree,它可以看作数据的多层压缩,试图保留数据内在的聚类结构。
- (可选)将第一步建立的CF Tree进行筛选,去除一些异常CF节点,这些节点一般里面的样本点很少。对于一些超球体距离非常近的元组进行合并。
- (可选)利用其它的一些聚类算法比如K-Means对所有的CF元组进行聚类,得到一颗比较好的CF Tree.这一步的主要目的是消除由于样本读入顺序导致的不合理的树结构,以及一些由于节点CF个数限制导致的树结构分裂。
- (可选)利用第三步生成的CF Tree的所有CF节点的质心,作为初始质心点,对所有的样本点按距离远近进行聚类。这样进一步减少了由于CF Tree的一些限制导致的聚类不合理的情况。
从上面可以看出,BIRCH算法的关键就是步骤1,也就是CF Tree的生成,其他步骤都是为了优化最后的聚类结果。
在构造完成CF-树以后,BIRCH采用某个(选定的)聚类算法对CF-树的叶子节点进行聚类,把稀疏的簇当做离群点删除,而把稠密的簇合并为更大的簇。这些聚类算法可以是k-means,或者分层凝聚法等。
BIRCH算法试图利用可用的资源来生成最好的聚类结果。通过一次扫描就可以进行较好的聚类,故该算法的计算复杂度是O(n),n是对象的数目。
优点:
- 节约内存,所有的样本都在磁盘上,CF Tree仅仅存了CF节点和对应的指针。
- 聚类速度快,只需要一遍扫描训练集就可以建立CF Tree,CF Tree的增删改都很快。
- 可以识别噪音点,还可以对数据集进行初步分类的预处理。
缺点:
- 由于CF Tree对每个节点的CF个数有限制,导致聚类的结果可能和真实的类别分布不同.
- 对高维特征的数据聚类效果不好。此时可以选择Mini Batch K-Means。
- 如果数据集的分布簇不是类似于超球体,或者说不是凸的,则聚类效果不好。
四、密度聚类方法
密度聚类方法的关键思想是通过检测局部密度变化来识别簇的边界,而不仅仅依赖于全局距离度量。密度聚类方法的指导思想是,只要一个区域中的点的密度大于某个域值,就把它加到与之相近的聚类中去。这使得密度聚类方法对不同形状、大小和密度的簇具有良好的适应性,并且对于噪声数据具有一定的鲁棒性。
4.1 DBSCAN算法
Visualizing DBSCAN Clustering (具象化演示网站)
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
一些重要概念:
- ε-邻域(Epsilon Neighborhood):ε-邻域是指以某个数据点为中心,半径为 ε 的圆形区域,包括了距离该点在 ε 范围内的所有数据点。ε-邻域是用来衡量数据点之间距离的局部范围。
- 核心对象(Core Object):在DBSCAN中,核心对象是指在 ε-邻域内至少包含 MinPts 个数据点的数据点。核心对象是密度高的数据点,是簇的中心。
- 直接密度可达(Directly Density-Reachable):如果数据点 A 在数据点 B 的 ε-邻域内,且数据点 B 是核心对象,那么数据点 A 被称为直接密度可达于数据点 B。这意味着数据点 A 可以通过 ε-邻域内的密度较高的核心对象 B 直接到达。但是不能说B可以通过A直接到达,除非A也是核心对象。即密度直达是不对称的。
- 密度可达(Density-Reachable):如果存在一条数据点序列 P1, P2, ..., Pn,其中 P1 = A,Pn = B,且对于任意相邻的数据点 Pi 和 Pi+1,Pi+1 是从 Pi 直接密度可达的,那么数据点 A 被称为密度可达于数据点 B。这表示通过一系列直接密度可达的数据点可以连接起点 A 和终点 B。密度可达也是不对称的。
- 密度相连(Density-Connected):如果存在一个数据点 C,使得数据点 A 和数据点 B 都是密度可达于数据点 C,那么数据点 A 和数据点 B 被称为密度相连。密度相连是一种传递性的关系。密度相连时对称的。
简要步骤:
DBSCAN算法根据密度可达关系求出所有密度相连样本的最大集合,将这些样本点作为同一个簇。DBSCAN算法任意选取一个核心对象作为“种子”,然后从“种子”出发寻找所有密度可达的其他核心对象,并且包含每个核心对象的ε-邻域的非核心对象,将这些核心对象和非核心对象作为一个簇。当寻找完成一个簇之后,选择还没有簇标记的其他核心对象,得到一个新的簇,反复执行这个过程,直到所有的核心对象都属于某一个簇为止。
具体步骤:
- 初始化:选择两个参数,Epsilon(ε)和MinPts。
- ε(Epsilon):表示半径,它用于定义一个数据点的邻域范围。 ε 决定了数据点在 ε-邻域内有多少个邻居。
- MinPts:表示在 ε-邻域内至少应包含的数据点数量。MinPts 用于确定核心点(密度足够高的点)。
- 选择起始点:从数据集中随机选择一个数据点作为起始点。
- 找到 ε-邻域:计算起始点到数据集中所有其他数据点的距离,并将距离小于 ε 的数据点视为起始点的 ε-邻域内的邻居。
- 核心点检测:如果 ε-邻域内的邻居数量不少于 MinPts,则将起始点标记为核心点。
- 扩展簇:如果起始点是核心点,那么开始从它的
ε-邻域内扩展簇。具体步骤如下:
- 将起始点添加到当前簇中。
- 对于 ε-邻域内的每个点,如果它是核心点,则将它的 ε-邻域内的邻居点也添加到当前簇中。
- 递归地继续扩展簇,直到没有更多的核心点可以添加。
- 找到下一个起始点:如果当前簇已扩展完毕,则从数据集中选择下一个未访问的核心点作为新的起始点,然后重复步骤 3 到步骤 5。
- 标记噪声点:所有未被分配到任何簇的数据点被视为噪声点。
- 结束:当所有数据点都被分配到簇或标记为噪声点时,DBSCAN算法结束。
DBSCAN的输出是一组簇,每个簇包含若干核心点和它们的密度可达的数据点,以及一些噪声点。DBSCAN的主要优点包括对不同形状和大小的簇具有良好的适应性,能够自动确定簇的数量,以及对噪声数据点有一定的鲁棒性。这使得它在实际应用中广泛使用,尤其适用于发现具有不规则形状的聚类结构。
优点:
- 能够自动识别不同形状和大小的簇:DBSCAN不依赖于簇的形状和大小,能够识别具有不规则形状的聚类结构。这使得它在实际应用中非常灵活。
- 对噪声数据有较好的鲁棒性:DBSCAN能够自动将噪声数据点识别为孤立点或离群点,而不将其分配给任何簇。
- 不需要提前指定簇的数量:与许多其他聚类算法不同,DBSCAN无需事先指定要找到的簇的数量,它能够根据数据的本地密度自动确定簇的数量。
缺点:
- 对参数敏感:DBSCAN需要用户事先指定两个关键参数:ε(邻域半径)和 MinPts(核心点最小邻居数)。不同的参数选择可能导致不同的聚类结果,因此参数的选择需要谨慎,可能需要进行试验和调整。
- 可能产生边界点和孤立点:DBSCAN将数据点划分为核心点、边界点和噪声点,但边界点有时可能与多个簇关联,导致歧义。此外,DBSCAN可能将簇分成多个部分,这取决于参数的设置和数据的分布。
- 不适用于数据密度差异很大的情况:如果数据集中存在密度差异非常大的区域,DBSCAN可能不适用,因为 ε 和 MinPts 参数需要在整个数据集上保持一定的一致性,这可能会导致无法识别低密度区域的簇。
4.2 OPTICS算法
(4)聚类算法之OPTICS算法 - 知乎 (zhihu.com)
机器学习笔记(十一)聚类算法OPTICS原理和实践_optics聚类-CSDN博客
在 DBSCAN 算法中,邻域参数(E,MimPts)是全局唯一的,当样本点的密度不均匀或聚类间相差很人时,聚类质量较差。此外,DBSCAN 算法对邻域参数(E,MinPts)非常敏感,需要由用户指定参数,参数设置的不同可能导致聚类结果差别很大,当用户不了解数据集特征时,很难得到良好的聚类结果。为了克服这些缺点,安克斯特(Ankerst) 等人提出了 OPTICS 算法。
OPTICS 也是基于密度的聚类算法,但这一算法生成一个增广的簇排序,即所有分析对象的线性表,代表各样本点基于密度的聚类结构。从线性表的排序中可以得到基于任何邻域参数(E,MinPts)的 DBSCAN 算法的聚类结果。
重要概念:
核心距离:对于一个给定的核心点X,使得X成为核心点的最小邻域距离 r 就是X的核心距离。
可达距离:假设 q 是核心点。那么点 p 和点 q 的可达距离定义为:
即,如果X是核心对象,则对象 Y 到对象 X 的可达距离就是Y到X的欧氏距离和X的核心距离的最大值,如果X不是核心对象,则Y和X之间的可达距离就没有意义(不存在可达距离)。
算法流程:
输入: 数据集 D。 输出: 有序的输出结果队列 R,以及相应的可达性距离。 初始化:创建两个队列,有序队列 O 和结果队列 R。
如果数据集 D 中还有未处理的点或者存在核心点,则执行以下步骤:
- 选择一个未处理且为核心对象的样本点 P。
- 将 P 放入结果队列 R 中,并从数据集 D 中删除 P。
- 找到样本点 P 在数据集 D 中的所有密度直达样本点
X,并计算 X 到 P 的可达距离。
- 如果 X 不在有序队列 O 中,则将 X 及其可达距离放入 O 中。
- 如果 X 已经在 O 中,检查如果 X 的新可达距离更小,则更新 X 的可达距离。
- 对有序队列 O 中的样本点按可达性距离从小到大进行排序。
- 如果有序队列 O 为空,则跳至步骤 1
- 如果有序队列 O 不为空,则执行以下步骤:
- 取出 O 中的第一个样本点 Y(即可达性距离最小的样本点)。
- 将 Y 放入结果队列 R 中,并从数据集 D 和有序队列 O 中删除 Y。
- 如果 Y 不是核心对象,则执行以下步骤:
- 重复步骤 5.1(即找 O 中剩余数据可达性距离最小的样本点)。
- 如果 Y 是核心对象,则执行以下步骤:
- 如果 Y 已经在结果序列中,则不处理
- 找到 Y 在数据集 D 中的所有密度直达样本点(如果某些点已经在结果序列中则跳过),并计算到 Y 的可达距离。
- 按照步骤 2 将所有 Y 的密度直达样本点更新到 O 中。
- 取出 O 中的第一个样本点 Y(即可达性距离最小的样本点)。
- 重复以上步骤,直到算法结束
通过分析输出结果队列 R 中的数据点顺序以及它们的可达性距离,可以确定数据点之间的聚类结构。不同密度级别的簇会以不同的形式出现在结果队列中。通常,连续的数据点(可达性距离较小的数据点)表示同一簇内的点,而可达性距离较大的数据点表示不同簇之间的分隔点。
4.3 DENCLUE算法
DENCLUE(Density-Based Clustering of Applications with Noise)是一种基于密度的聚类算法,用于在数据集中发现聚类簇和噪声点。该算法通过建模数据点的局部密度分布来识别聚类簇,并使用核密度估计来确定数据点的聚类结构。以下是DENCLUE算法的关键特点和步骤:
其核心思想可以概括为以下几点:
- 影响函数(Influence Function): DENCLUE将每个数据点的影响(影响其邻域的程度)形式化建模为一个数学函数,称为影响函数。这个函数描述了一个数据点对其周围邻域的影响程度,通常是一个随距离递减的函数。影响函数的选择可以根据问题的特性和数据的性质进行调整。
- 整体密度建模: DENCLUE通过将所有数据点的影响函数叠加在一起来建模数据空间的整体密度。这表示整体密度是由每个数据点的局部影响共同构成的,而不是简单地假定所有数据点具有相同的密度。这使得DENCLUE能够捕获数据集中不同区域的密度差异。
- 密度吸引点(Density Attractor): 簇可以通过寻找全局密度函数的局部最大值来确定。在DENCLUE中,这些局部最大值被称为密度吸引点。密度吸引点表示数据集中的密度高点或局部聚类中心,因为它们是整体密度函数的局部极大值。DENCLUE的目标之一是识别这些密度吸引点,因为它们对应于聚类簇的核心。
优点:
- 对不规则形状和不均匀密度的聚类适应性好: DENCLUE能够发现各种形状的聚类簇,包括不规则形状和密度不均匀的簇,因为它基于数据点的局部密度分布进行建模。
- 对噪声点具有鲁棒性: DENCLUE可以有效地将噪声点识别为未连接到任何密度吸引点的数据点,这使得它对数据中的噪声具有较好的鲁棒性。
- 对密度变化敏感: 由于DENCLUE使用核密度估计来描述数据点的局部密度,因此它对密度的变化和梯度变化敏感,能够在数据集中捕获密度的细微差异。
缺点:
- 计算复杂度高: DENCLUE的计算复杂度较高,特别是在大规模数据集上运行时,需要处理大量的局部密度估计和梯度计算,因此在处理大数据时可能效率较低。
- 对参数敏感: DENCLUE需要设置一些参数,如影响函数和吸引子生成的停止条件。选择适当的参数值可能需要一些经验或试验,不合适的参数值可能会影响聚类结果。
五、其它聚类方法
5.1 WaveCluster:小波变换聚类
WaveCluster 是一种基于小波变换的聚类算法,旨在处理具有噪声和异常值的数据集。该算法利用小波变换技术来提取数据的特征,从而能够识别出不同尺度和密度的聚类簇。以下是 WaveCluster 算法的主要特点和步骤:
主要特点:
- 小波变换: WaveCluster 使用小波变换来分析数据的频率和尺度特征。小波变换是一种信号处理技术,可将数据转换为不同尺度上的频域信息,从而更好地捕获数据中的结构。
- 自适应阈值: WaveCluster 使用自适应阈值来检测噪声和异常值。这有助于排除不符合聚类结构的数据点,提高聚类的鲁棒性。
- 多尺度聚类: WaveCluster 能够识别不同尺度上的聚类结构,因此对于具有多个尺度的数据集特别有用。它可以处理具有不同密度和尺度的簇。
算法步骤:
- 小波变换: 将数据应用小波变换,将数据转换为小波域,得到小波系数。这些小波系数包含了不同尺度和频率上的数据特征。
- 聚类分析: 对小波系数进行聚类分析,以识别具有相似特征的数据点。通常,使用一些聚类方法来对小波系数进行聚类,例如K均值聚类。
- 噪声过滤: 使用自适应阈值来过滤掉被认为是噪声的数据点,以提高聚类的准确性。
- 簇合并: 将具有相似特征的小波系数聚合到一起,以形成最终的聚类簇。
- 可视化和分析: 最后,对聚类结果进行可视化和分析,以了解数据的聚类结构和特征。
小波变换在聚类中是有用的:
- 提供无指导聚类: 小波变换可以提供无指导聚类,因为它通过帽形过滤(wavelet thresholding)可以强调点密集的区域,并忽视在密集区域以外的较弱信息。这有助于识别数据集中的聚类结构,而无需事先指定簇的数量或形状。
- 有效去除孤立点: 小波变换可以有效地去除孤立的离群点或噪声,因为这些点通常在小波变换后的系数中表现为低幅度的信号,可以通过阈值处理来剔除。
- 多分辨率: 小波变换是一种多分辨率分析方法,可以捕获数据在不同尺度上的特征。这允许小波变换识别具有不同尺度的聚类结构,从细粒度到粗粒度。
- 有效花销: 小波变换的计算复杂性通常是线性的,因此在一些情况下,它可以更高效地处理大规模数据集。
主要特征:
- 复杂度O(N): 小波变换的复杂性通常是线性的,因此它适用于大型数据集。
- 发现不同比例的任意形状的簇: 小波变换可以检测不同比例和形状的聚类簇,因为它在多个尺度上分析数据。
- 对噪声和输入次序不敏感: 小波变换具有一定的噪声鲁棒性,可以有效地处理一些噪声数据。此外,它对输入数据的次序不敏感,因此对于不同排列的数据点也能产生相似的结果。
- 只能应用与低维度的数据。
第五章 网络事件检测与跟踪
一、网络舆情概述
概念:网络舆情是指在互联网背景之下,众多网民关于社会(现实社会、虚拟社会)各种现象、问题所表达的信念、态度、意见和情绪表现的总和,或简言之为网络舆论和民情。
网络舆情的存活时间:大多集中在两周以内,如果回应不当,可能持续到21天左右。
网络舆情监控和预警
- 发生期
- 发酵期
- 发展期
- 高涨期
- 回落期
- 反馈期
网络舆情的特点:
直接性
网络舆情不像报纸、杂志和电视,要经过报选题、采访、编辑、审稿、发布或者播放等几个环节,而网民发帖,就没有中间环节,很直接,随意性很强,网络舆情发生以后,网民可以直接通过网站论坛、微信、QQ空间、博客等载体立即发表意见
突发性
就是无法预测,突然发生,网络舆论的形成往往非常迅速,一个热点事件的存在加上一种情绪化的意见,就可以成为点燃一片舆论的导火索。
偏差性
就是所表达的观点,与实际不符合,由于发言者身份隐蔽,并且缺少规则限制和有效监督,网络自然成为一些网民发泄情绪的空间。
网络舆情危机的传播路径
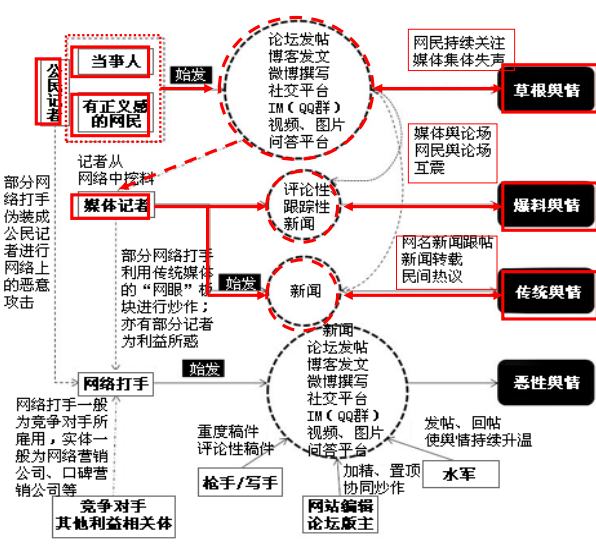
组成部分:
信源:事件。
社会问题、个人意见、重大事件、社会心理、意见领袖引导是当今网络舆情的五大因素。
网民:网络舆情的传播者。
网民是多种情绪、态度和意见的持有者, 其核心是社会政治态度。网民通过网络发表舆情言论成为引导和影响舆论的重要力量。网民是对民生、公民权利、公共治理最敏感、最敢言也最擅说话的人群,“网络舆论”可作为现实民意的风向标和参照系。
违法违规网络公关手段——“网络水军”、“网络推手”、“灌水公司”、“删帖公司”、“投票公司”等形形色色的非法网络公关机构,利用不正当手段打击竞争对手、歪曲捏造事实进行敲诈勒索、通过话题炒作制造虚假网络民意牟利、从事私下交易牟取非法利益等。
二、网络谣言
- 定义:广义:社会中出现并流传的未经官方公开证实或者已经被官方证伪了的信息。狭义:指没有事实根据的或凭空虚构的虚假信息。
- 网络谣言的传播速度更快、周期更短、波及范围更广、表现形式更多样、隐蔽性更强。
- 网络谣言的类型:
- 政治谣言
- 经济谣言
- 军事谣言
- 社会民生谣言
- 自然现象谣言
- 生成原因:
- 外部环境:国际局势错综复杂,政治谣言作为各方博弈的“攻心利器” ,在舆论场上屡见不鲜。
- 社会治理中也不可避免地出现了某些诸如“落实依法行政不力”等公共管理失范现象,群体焦虑情绪易被放大。
- 商业竞争激烈。
- 媒体行业规范,部分媒体为在市场竞争中取得优势,未能严守新闻职业操守及行业规范, 导致报道失实。
- 公民素养也是决定网络谣言产生及发酵程度的重要原因之一,即涉事主体信息公开程度越高,公民素养越高(识别信息真实性的能力越强),谣言产生的可能性就越小,谣言强度越弱。
- 谣言的强度=事件的重要性×事件信息的模糊性÷公众批判能力。
- 鉴别方法:
- 发布主体:信息转手次数越多,越容易失真,一手信源更容易辨别真伪。
- 信息内容:时间地点人物清晰可回溯,信源多元均衡,核查物证,内容前后无矛盾。
三、网络水军
定义:传统的网络“水军”是指以获取收益为主要诉求,受雇于公关公司或者营销公司,在短时间内通过大量发帖、转帖、回帖等方式满足雇佣者建构舆论、制造荣誉或恶意抹黑的特定需求,是互联网时代背景与商业需求结合的产物,也是网络营销的常用手段之一。
随着人工智能等计算机技术的发展,机器人“水军”也应运而生。
运作模式:
- 需求方:企业电商等
- 中介方:公关公司、网络推广公司
- 服务提供方:社会上闲散人员
危害:
- 助推谣言发生
- 制造大量网络噪声
- 干扰正常社会生产秩序
- 产生违法犯罪行为
类型:
- 营销型
- 公关型
- 抹黑型
检测方法:
文本内容特征:
有强烈的情感倾向,水军群体活动多以评论转发点赞为主,主动发帖少,内容包含大量商业广告和垃圾信息
账号信息特征:
账号创建时间短,名称随机,活动时间集中
用户关系特征:
正常用户的常规活动会有与亲朋好友之间的互关、互动;而水军账号多是单向的,大范围关注正常账号但是回关概率低,并且关系紧密度低。
四、话题检测与跟踪
报道(Story):指新闻文章或者新闻电视广播中的片段,至少包含一个完整的句子。通常情况下,一篇报道只描述一个话题,但是也有些报道涉及多个话题。
事件(Event):事件是指发生在特定时间和地点的事情,涉及了某些人和物,并且可能产生某些必然的结果。
话题(topic):一个话题由一个种子事件或活动以及与其直接相关的事件或活动组成。因此,也可以认为话题是一个相关事件的集合,或者是若干对某事件相关报道的集合。
主题(subject):一类事件或话题的概括,它涵盖多个类似的具体事件,或者根本不涉及任何具体的事件,主题比话题的含义更广。
话题检测与跟踪(topic detection and tracking,TDT)任务:
报道切分(SST)
一段报道可能包括多条新闻,需要切分
话题检测(TD)
将讨论同一个话题的报道聚到同一个桶(bin)中,bin的创建为无监督。
设计一个善于检测和识别所有话题的检测模型,并根据这一模型检测陆续到达的报道流,从中鉴别最新的话题;同时还需要根据已经识别到的话题,收集后续与其相关的报道。
首次报道检测任务(FSD)
检测什么时候出现了一个新话题,这个话题以前没有报道过。
FSD与TD面向的问题基本类似,但是 FSD 输出的是一篇报道,而TD输出的是一类相关于某一话题的报道集合。
话题跟踪(TT)
给定某个话题的数篇相关报道,TT识别数据流中讨论该话题的后续报道。
关联检测(LD)
给定两篇报道,判断其是否属于同一个话题。
4.1 话题表示与关联检测 TDT(Topic Detection and Tracking)
话题表示模型主要采用文本表示模型。常用的模型分为向量空间模型和语言模型。
1. 向量空间模型
- 这种模型基于词袋表示法,将文本中的词汇映射到高维向量空间中,其中每个维度对应一个词汇。
- 常见的向量化方法包括词袋模型(Bag of Words, BoW)、TF-IDF(Term Frequency-Inverse Document Frequency)等。
- 通过计算文本之间的向量相似度(如余弦相似度),可以用来衡量文本之间的关联程度。
TDT中通常涉及的三个不同方面的相似性,以及它们对应的对象:
- 报道与报道的相似度:这表示在TDT任务中,要评估两篇不同报道之间的相似性程度。这可以帮助确定两篇报道是否涉及相似的话题或事件。
- 话题与报道的相似度:这表示要评估某个特定话题或主题与一篇报道之间的相似性。这可以用来确定一篇报道是否与某个特定话题相关。
- 话题与话题的相似度:这表示要评估两个不同话题或主题之间的相似性程度。这有助于识别话题之间的关联或相似性,以及它们如何在不同报道中出现。
这三种相似性评估对应着不同的对象:
- 两篇文本:在第一个方面中,相似性是在两篇不同的报道或文本之间进行评估,以确定它们之间的相似性。
- 一篇文本与一个文本集合:在第二个方面中,相似性是评估一篇特定报道或文本与一个包含多篇文本的集合之间的相似性。
- 两个文本集合之间的相似度:在第三个方面中,相似性是用来比较两个不同的文本集合之间的相似性程度,以了解它们包含的话题或事件是否相似。
基于向量空间模型,判断两篇报道是否讨论了相同的话题或主题的步骤:
- 向量化报道:首先,将每篇报道表示为一个向量。这个向量通常是基于向量空间模型的表示,其中每个维度对应于文档中的一个特征或词项。这个向量可以使用词袋模型、TF-IDF权重或其他文本表示方法生成。
- 计算相似度:然后,使用向量余弦距离计算方法来度量两个报道向量之间的相似度。余弦距离是一种常用的相似度度量方法,它衡量了两个向量之间的夹角,从而表示它们在向量空间中的方向一致性。
- 设置阈值:在这个方法中,需要设定一个相似度阈值。这个阈值通常是一个预先定义的值,可以根据具体的任务和数据集进行调整。阈值的选择会影响最终的关联检测结果。
- 判断关联:最后,将计算得到的相似度与设定的阈值进行比较。如果两篇报道的相似度大于阈值,那么就认为它们讨论了相同的话题或主题,即它们具有关联性。反之,如果相似度小于阈值,那么就认为它们不讨论相同的话题。
一篇报道和一个话题之间的相似度计算的核心问题确实涉及向量之间的相似度。在关联检测任务中,通常有两种主要方法来计算一篇报道和一个话题之间的相似度:
- 计算报道与构成该话题的所有报道之间的相似度:
- 这种方法涉及将一篇报道与话题中的每一篇报道进行相似度计算。
- 对于每对报道之间的相似度计算都是一次关联检测的过程。通过比较一篇报道与话题中的每篇报道,可以确定它与话题的相关性。
- 通常,可以使用向量空间模型或其他文本表示方法来计算报道之间的相似度。
- 将话题表示成一个中心向量(话题模型):
- 这种方法涉及将整个话题表示为一个中心向量,通常是话题中所有报道的平均向量或加权平均向量。
- 这个中心向量代表了话题的整体特征。一篇报道与话题之间的相似度可以通过计算报道向量与话题中心向量之间的相似度来确定。
- 这种方法的好处是减少了计算的复杂性,因为不需要对每对报道之间进行相似度计算。相反,只需要计算一次话题中心向量和一篇报道之间的相似度。
2. 语言模型
使用Kullback-Leibler(K-L)距离是一种衡量两个概率分布之间差异或相似度的方法,可以用于计算报道与话题之间的相似度,特别是当将文本表示为概率分布时。
以下是使用K-L距离计算报道与话题之间的相似度的一般步骤:
文本表示成概率分布:
首先,将报道和话题分别表示为概率分布。这可以通过词项的概率分布来实现,其中每个词项的概率表示在文本中出现的频率或权重。通常使用TF-IDF等方法来计算这些概率分布。
计算K-L距离:
使用K-L距离公式计算报道分布(P)和话题分布(Q)之间的距离,公式如下所示:
其中,x代表不同的词项,P(x)是报道中词项x的概率,Q(x)是话题中词项x的概率。 相似度度量:
K-L距离计算的结果是一个非负数,表示两个分布之间的差异。为了将其转化为相似度度量,可以考虑使用以下方法之一:
- 可以使用K-L距离的倒数来得到相似性度量,即相似度 = 1 / (1 + K-L距离)。
- 也可以使用指数函数对K-L距离进行转换,例如,相似度 = exp(-K-L距离)。
阈值设定:
最后,可以根据具体任务需求,将计算得到的相似度值与预先设定的阈值进行比较。如果相似度值高于阈值,则认为报道与话题之间存在相关性,否则认为它们不相关。
需要注意的是,K-L距离在计算时要小心处理分布中的零概率问题,以及在面对长尾词汇时的平滑方法。
为了避免零概率问题,对概率值进行平滑处理:
4.2 话题检测
话题检测的目标是从连续的报道数据流中检测出新话题或者此前没有定义的话题。
系统对于话题的主题内容、发生时间和报道数量等信息是未知的,也没有可以用于学习的标注样本。
话题检测是一个无监督的学习任务,通常采用聚类算法来实现。
话题检测处理的对象是按时间排序的报道数据流,具有明确的时间顺序关系。数据流中的话题往往是动态演化的,不同的时间段话题的讨论内容可能不一样。
话题检测通常分为:
在线检测(online detection,也称为新事件检测New eventdetection:NED)
输入是实时的报道数据流,当前时刻的后续报道是不可见的,在每个新报道出现时,要求系统能够在线判断该报道是否属于一个新的事件。
回溯检测(retrospectivedetection:RED)
输入是包含所有时刻的完整数据集,要求系统离线地判断数据集中的报道所属的事件,并相应的将整个数据集分成若干个事件片段。
1. 在线话题检测
采用增量式的在线聚类算法,即单遍聚类算法(single-pass slustering)
算法的主要步骤:
- 处理输入报道:算法按照报道的顺序逐一处理输入的报道。每篇报道被表示为一个向量,其中的特征项可以是报道中的词或短语,特征的权重使用TF-IDF或其变体进行计算。
- 计算相似度:对于每篇新报道,算法计算它与所有已知话题之间的相似度。这里的相似度是指新报道与话题的中心向量或平均向量之间的相似度。
- 归类报道:如果相似度值高于预设的合并阈值,就将新报道归类到与其相似度最高的话题中。这意味着新报道被认为与该话题相关。如果相似度值低于分裂阈值,算法将创建一个新的类簇来表示新话题,并将新报道放入该类簇中。如果处于两者之间,则不处理。
- 反复执行:重复执行上述步骤,处理每篇新报道,直到所有的报道都被处理一遍。
- 形成扁平聚类:最终,算法将形成一个扁平聚类,其中每个类簇代表一个话题或一个相关报道的集合。簇的个数取决于合并-分裂阈值的大小,较低的阈值可能导致更多的话题被检测到,而较高的阈值可能导致合并相似的话题。
一些改进:
每篇报道的内容被表示为一个查询,查询的特征项是动态变化的,是由数据流中所有已出现文档的前n个高频词组成的。随着时间的变化,以前所有的查询表示都需要在新的特征项上更新一遍。
由于未来的报道在实时环境下是未知的,需要根据一个辅助语料c来 计算IDF,这个辅助语料要与当前检测的文本数据流属于同一个领域, 计算方法如下:

进一步的研究表明,新闻报道的时间特征有助于提高在线话题检测的性能,数据流中时间接近的报道更有可能讨论相同的话题。因此,可以在阈值模型中增加时间惩罚因子,当第j篇报道与第i个查询(i<j )进行比较时,相应的阈值定义如下:

2. 回溯话题检测
基于平均分组的层次聚类算法(GAC)是针对回溯检测(RED)的一种较好算法
GAC是一种自底向上的谈心算法,采用了分而治之的策略。能够最大化话题类簇中各新闻报道之间的平均相似度。输入为按照时间排序好的新闻文档集合,输出为层次式话题类簇结构。
算法基本流程:
初始化:
开始时,每篇文档被视为一个单独的话题类簇。
桶的划分:
将当前的话题类簇按照顺序连续划分到大小为m的"桶"中。这里的"桶"是一种临时容器,用于组织和处理话题类簇。
桶内聚类:
- 对每个桶中的话题类簇进行聚类操作。
- 聚类的过程采用自底向上的方式,即逐步合并最相似的底层话题类簇,以形成一个高层次的话题类簇。合并是基于两个类簇之间的相似度来完成的。
- 这个合并过程一直持续,直到达到预设的合并条件,可以是类簇数量减少的比例达到预设p,或者任何两个类簇之间的相似度值均低于一个预定义的阈值s。
桶的边界去除:
在保持各话题类簇事件顺序的前提下,去除桶的边界,将所有桶中的话题类簇汇集到一起。此时,得到了当前的类簇集合。
重复步骤2-4:
重复步骤2到步骤4,直到最顶层的话题类簇数目达到了预定的数值。
定期重新聚类:
定期对每个顶层类簇中的所有新闻文档进行重新聚类,按照前五步的方法。
4.3 话题跟踪
话题跟踪的主要任务是对特定话题进行追踪,即给定与特定话题相关的少量报道,检测出新闻报道流中与该话题相关的后续报道。
从信息检索的角度来看,话题跟踪与信息过滤有一些相似之处,因此可以借鉴信息过滤中的查询方法来进行话题跟踪。以下是如何利用信息过滤的查询方法进行话题跟踪的一般步骤:
建立查询器:
首先,需要建立一个查询器,该查询器用于表示待跟踪的话题。这个查询器的构建是基于话题的训练语料。训练语料包括一些已知与待跟踪话题相关的报道作为正例样本,以及其他不相关的报道作为负例样本。
查询器的目标是捕捉与待跟踪话题相关的关键词、短语或特征。
查询器的构件方法有两种:基于向量空间模型、基于语言模型
计算相似度:
对于每篇后续报道,使用建立的查询器来计算查询器与报道之间的相似度。这可以使用不同的相似性度量方法来实现,例如余弦相似度。
相似度阈值:
设定一个相似度阈值,用于判断报道是否属于待跟踪的话题。如果报道与查询器的相似度高于设定的阈值,那么可以认为这篇报道与待跟踪话题相关。
跟踪与筛选:
随着新报道的到来,计算它们与查询器的相似度,并与相似度阈值进行比较。如果相似度高于阈值,将报道纳入待跟踪话题的跟踪范围。否则,可以将其排除,认为不属于该话题。
实时更新:
设定一个查询器调整阈值,当报道相似度大于查询器调整阈值时,重构查询器以吸收该话题的重要特征,定期或实时地更新查询器,以适应话题的变化和演化。
KNN算法基本步骤:
- 计算待测数据点与所有训练数据的距离;
- 距离值递增排序;
- 选出前K个最小距离;
- 统计这K个距离值所对应的标签的频数;
- 频数最大的标签即为预测类别。
五、社交网络突发事件检测
社交媒体特征:
- 微博短文本限制:140个字
- 向量稀疏
- 特征词的文档频数分布是一个长尾分布,大部分的特征词都只在较少的微博中出现
突发特征检测方法:
- 假设检验方法:
- 这种方法假设在一个给定的时间窗口内,特征词的生成概率服从正态分布。
- 特征词的频率如果大于某个阈值,而且在该时间窗口内处于突发状态的概率小于5%,则被认为是突发特征词。
- 引入能量值方法:
- 这个方法引入了能量值的概念,考虑了频率和发帖者的权威度。
- 根据过去几个时间窗口内特征的权重值计算当前窗口内的能量值,增长速度越大,能量值越大。
- 使用监督或无监督方法来根据能量值判断是否为突发特征词。
- Kleinberg的方法:
- Kleinberg提出了一种使用隐马尔科夫模型(HMM)来表示特征词生成过程的方法。
- 特征词在每个时间窗口内都处于一个状态,并以相应的概率被生成。
- 突发状态对应于高频率,状态之间的转移需要付出代价。
- 通过Viterbi算法求解HMM,确定最可能的状态序列,从而检测突发特征词。
第六章 社交网络分析
一、基本概念
社交网络分析(Social Network Analysis, SNA)实际上就是利用网络科学理论来研究社会关系。其中,网络中的结点代表网络中的参与者(actor),结点之间的连线代表参与者之间的相互关系。
SNA主要关注交互,而不是个体行为。
SNA可用于分析网络的配置(configuration)如何影响个体和群体、组织或系统功能。
主要研究包括:
- 结点排序:研究结点相似度,之间可能存在连边
- 链路预测:基于网络关系对缺失信息的还原、对将来信息的预测
- 信息传播:研究信息的的传播模式和过程。包括影响力最大化、信息扩散模型等
主要应用于:
- 社交推荐
- 舆情分析
- 隐私保护
- 用户画像
- 可视化
六度分隔理论:“最多通过六个人你就能够认识任何一个陌生人。” 六度分隔说明了社会中普遍存在的“弱纽带”,但是却发挥着非常强大的作用。
150法则:150成为我们普遍公认的“我们可以与之保持社交关系的人数的最大值。”
SNA的挑战:
- 需要在本地、特定于客户的信息与网络信息之间找到正确的平衡
- 需要同时推断所有节点行为的过程(集体推理程序)
- 训练和测试集不易分离
二、结点排序
社交网络分析的核心问题是如何识别网络中的重要结点。 重要结点是指相比网络中其他结点而言能够在更大程度上影响网络结构特征与功能的一些特殊结点。 重要结点的数量一般非常少,但其影响可以快速传播到网络中的大多数结点。
定义:
- 拓扑图记为:
,结点集合: ,边的集合: ,n和m是结点数和边数。 - 一个图的邻接矩阵记为:
,当两节点有边时记为权重值(无带权网络记为1),否则记为0。 - 网络中的一条路径是类似这样的一组结点和边的交替序列:
2.1 基于结点近邻的排序方法
最简单、最直观的方法:度中心性、K-壳分解
1. 度中心性
在社交网络分析中,结点的重要性也称中心性,其主要观点是结点的重要性等价于该结点与其他结点的连接使其具有的显著特性。度中心性认为一个结点的邻居数目越多,其影响力就越大,这是网络中刻划结点重要性最简单的指标。
在有向图中,度中心性还需考虑结点的入度和出度。在带权网络中,还需考虑权重值。总的来讲,度中心性刻划的是结点的直接影响力,它认为一个结点的度越大,能直接影响的邻居就越多,换句话说就是该结点越重要。
2. K-壳分解
此方法将外围的结点层层剥去,处于内层的结点拥有较高的影响力。
初始化:
假设网络中不存在度数为0的孤立结点。度数为1的结点是网络中最不重要的结点,首先从网络中删除度数为1的节点及其边。
迭代过程:
循环执行以下步骤,直到网络中不再存在度数为1的节点:
- 从网络中删除度数为1的节点及其边。
- 检查删除操作后是否会产生新的度数为1的节点。
- 如果有新的度数为1的节点出现,继续执行步骤a;否则,执行下一步。
确定第一层(1-shell):
所有被删除的节点构成了第一层,其Ks值等于1。此时,剩余网络中的每个节点的度至少为2。
继续迭代:
重复上述迭代过程,依次删除度数为1的节点,构建第二层(2-shell),第三层(3-shell),以此类推,直到网络中的所有节点都获得了Ks值。
2.2 基于路径的排序方法
1. 接近中心性(closeness centrality)
接近中心性通过计算结点与网络中其他所有结点的距离的平均值来消除特殊值的干扰。
一个结点与网络中其他结点的平均距离越小,该结点的接近中心性就越大。 接近中心性也可以理解为利用信息在网络中的平均传播时长来确定结点的重要性。
计算任意一个结点
2. Katz中心性
Katz中心性是一种用于分析网络中节点重要性的中心性度量方法。与接近中心性不同,Katz中心性不仅考虑节点之间的最短路径,还考虑它们之间的其他非最短路径。这个度量方法利用一个参数s(s ∈ (0, 1))来衡量路径的权重,其中s是一个固定参数。
Katz中心性的计算基于网络中的路径关系矩阵,其中l(p)ij表示从节点vi到vj经过长度为p的路径的数目。通常,路径越短,权重越大。
3. 介数中心性(betweenness centrality)
通常提到的介数中心性一般指最短路径介数中心性(shortest path BC),它认为网络中所有结点对的最短路径中,经过一个结点的最短路径数越多,这个结点就越重要。
介数中心性指的是结点充当两个结点之间的短路路径的次数。结点充当“中介”的次数越多,介数中心性就越大。
结点
2.3 基于特征向量的排序方法
前述方法主要从邻居的数量上考虑对结点重要性的影响,基于特征向量的方法同时考虑了结点邻居数量和其质量两个因素。
1. 特征向量中心性(eigenvector centrality)
特征向量中心性认为一个结点的重要性既取决于其邻居结点的数量(该结点的度),也取决于每个邻居结点的重要性。
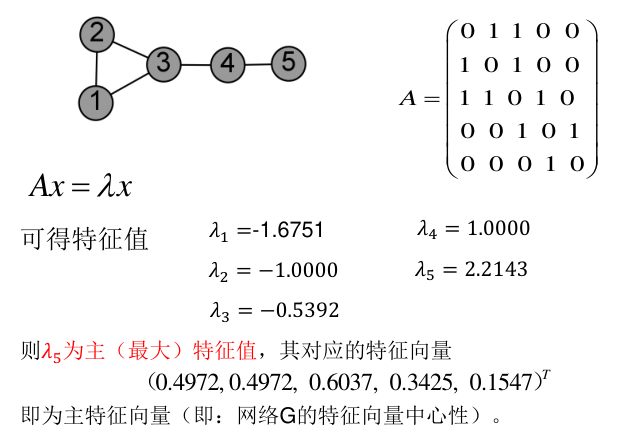
2. PageRank算法
PageRank是一种度量结点间传递影响或连通性的算法,可以通过在相邻结点上迭代分配一个结点的秩来计算,也可以通过随机遍历图并计算在这些遍历过程中到达每个结点的频率来计算。
三、链路预测
链路预测处理的是信息科学中最基本的问题——缺失信息的还原与预测。
链路预测根据某一时刻可用的结点及结构信息,来预测结点和结点之间出现链路的概率。链路预测任务实际上可被分为两类:
- 第一类是预测新链路将在未来出现的可能性,
- 第二类是预测当前网络结构中存在的缺失链路的可能性。
3.1 基于结点属性的相似性指标
前提假设是两个结点之间的相似性越大,两个结点之间存在链路的可能性越大。
有许多方法可以表示结点相似性,但最简单的方法是使用结点属性。如果他们具有相同的年龄、性别、职业和兴趣,则他们之间的相似性非常大。
3.2 基于局部信息的相似性指标
基于网络结构相似性的方法假设为:在网络中,两个结点之间相似性(或相近性)越大,它们之间存在连边的可能性就越大。
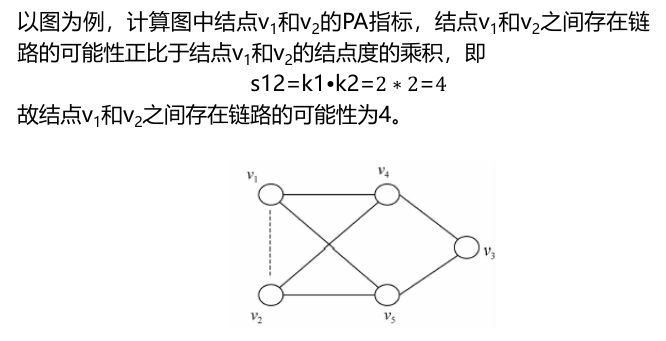
1. 优先连接指标(preferential attachment,PA)
优先连接方法的主要思想是:在网络中,一条即将加入的新边连接到结点x的概率正比于结点x的度,从而在结点x和结点y之间产生一条链路的可能性正比于两结点度的乘积,即:
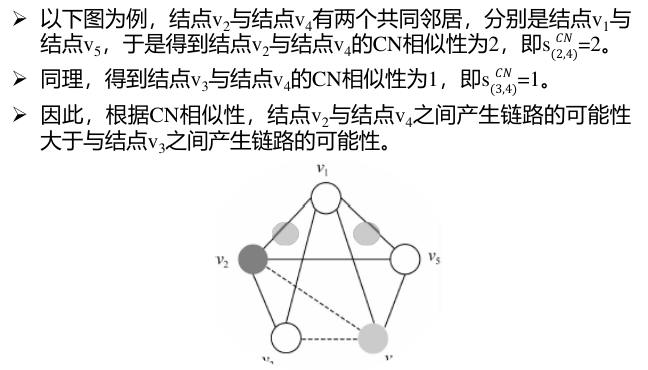
2. 共同邻居指标(common neighbor,CN)
共同邻居定义两个结点产生链路的可能性正比于它们之间的共同邻居的数量。
例如,在社交网络中,如果两个陌生人有很多共同的朋友,那么这两个人成为朋友的可能性就比较大。
3. AA指标
他们根据共同邻居结点的度为每个结点赋予一个权重值,该权重等于该结点的度的对数分之一,从而AA
指标就等于两个结点的所有共同邻居的权重值之和。
4. 资源分配指标(resource allocation,RA)
此方法假设每个结点都有一个资源单元,它将这些资源平均分配给它的邻居。
在没有直接连接的结点对vx和vy中,结点vx可以通过它们的共同邻居(kz为共同邻居结点的度,Tx为vx的邻居结点的集合)将一些资源分配给结点vy。因此,结点vx和vy的相似性可以定义为结点vy从结点vx获得的资源数量。
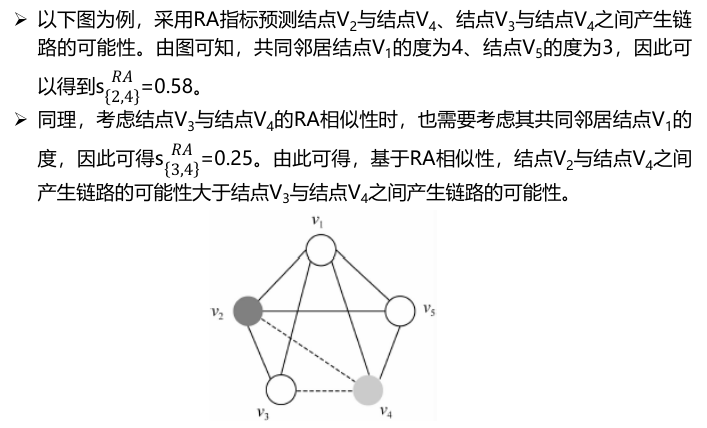
3.3 基于路径的相似性指标
1. 路径指标LP(local path)
同邻居指标可以看成考虑两个结点间的二阶路径数目的方法,如果在二阶路径基础上再考虑结点间的三阶路径数,就可以得到局部路径指标LP,定义为:
当α=0,LP指标就退化为CN指标,CN指标本质上也可以看成基于路径的指标,只是它只考虑二阶路径数目。
四、信息扩散模型
1. 线性阈值模型(Linear Threshold Model)
线性阈值模型( Linear Threshold Model) - 独立级联模型(Independent Cascade Model) - 言非 - 博客园
该模型表明:如果一个用户的采取行动的朋友的数量超过某个阈值,那么该用户才采取行动。
在线性阈值模型(Linear Threshold Model,LTM)中,每个结点 V
在0~1内均匀分布随机抽取一个阈值
2. 独立级联模型(Independent Cascade Model)
独立级联模型( Independent Cascade Model,ICM)借鉴了交互粒子系统( interac-ting particle)和概率论的理念。
与线性阈值模型不同,该模型关注信息的发送者( sender)胜过信息的接收者(receiver)。
在独立级联模型中,一个 结点w 一旦在 第t步
被激活,它只有一次机会激活它的邻接结点。 对于其
邻接结点v ,其被 结点w 激活的概率为
如果 v 被成功地激活,那么 v 就是 第 t+1 步 被激活的结点。在往后的信息扩散过程中, w 将不再试图去激活它其余的邻接结点。
在独立级联模型中,信息扩散过程与线性阈值模型的信息扩散过程相同,都从一个初始活动的结点集合开始,直到没有结点可以被激活而结束。
区别:
线性阈值模型
- 以接收者为中心(receiver-centered),通过观察一个结点的所有邻接结点,根据该结点的阈值决定是否可以激活该结点;
- 结点的激活依赖于一个结点的全部邻接结点;
- 一旦给定线性阈值模型中的阈值,网络中的信息扩散过程也就确定了。
独立级联模型
- 以发送者为中心(sender-cen-tered)。当一个结点被激活后,它试图去激活它的所有邻接结点;
- 一个结点独立地激活其所有的邻接结点(不一定都被激活);
- 信息扩散的过程随信息的级联过程(cascading process)而变。网络中的信息扩散过程不确定了。
3. 影响力最大化问题
影响力最大化(Influence Maximization)是社交网络分析和信息扩散理论中的一个关键概念。它关注的核心问题是在一个给定的网络中找到一个最优的节点集合(称为种子集合),使得通过这些节点启动的信息传播能够影响尽可能多的其他节点。
影响力最大化问题通常通过贪心算法进行求解,其步骤大致如下:
- 初始化种子集合:起始时种子集合为空。
- 迭代选择节点:分多轮进行,每轮从网络中选择一个能带来最大影响力增量的节点加入到种子集合中。
- 评估影响力:使用特定的信息扩散模型(如独立级联模型或线性阈值模型)来评估加入新节点后种子集合的影响力。
- 重复直至满足条件:一般是迭代次数,或种子集合达到预定大小。
4. 感染模型
感染模型常用的有:
- Susceptible-Infected-Recovered (SIR) 模型
- Susceptible-Infected-Susceptible (SIS) 模型
这个模型将人群分为三个部分:易感者(Susceptible)、感染者(Infected)、和移除者(Recovered或Removed)。
组件解释:
易感者 (S):这部分人群尚未感染疾病,但由于没有免疫力,他们有可能被感染。在信息传播的背景下,这些人尚未接收到特定信息。
感染者 (I):这部分人群已经感染疾病,并且具有传播病原体给易感者的能力。在信息传播的背景下,这些人已经接收到信息,并且可能将信息传播给其他人。
移除者 (R):这部分人群曾经感染过疾病,但现在已经康复,获得免疫力,不再传播病原体。在信息传播的背景下,这些人可能已经失去传播信息的兴趣或能力。
关键参数:
- 感染率(β):易感者变成感染者的速率。这通常与感染者的密度和两者之间的接触频率有关。
- 恢复率(γ/δ):感染者变成移除者的速率。这个率反映了病程的平均持续时间。
5. SIR模型
SIR适用于对每个人一生中只能感染一次的病毒进行建模。
算法过程:
初始化状态
所有节点分为三种状态:易感者(S),感染者(I),和移除者(R)。
初始时,部分节点被设定为感染状态(I),其他节点为易感状态(S)。
移除状态(R)的节点初始时数量为零。
模拟传播
对于每一个时间步长(step):
遍历所有处于感染状态(I)的节点。
对于每个感染节点:
- 遍历其所有易感(S)状态的邻居节点。
- 对每个易感邻居,有概率 p 使其变为感染状态(I)。这个概率 p 代表传染概率。
- 每个感染节点在感染状态保持 t 个时间步长。
- 遍历其所有易感(S)状态的邻居节点。
更新状态
对于处于感染状态(I)的节点,跟踪其在感染状态下经过的时间步长。
一旦某个感染节点在感染状态保持了 t 个时间步长,将其状态更新为移除状态(R)。
进入移除状态(R)的节点不再参与传播过程,也不会再被感染。
迭代
重复步骤2和步骤3,直到达到预设的模拟时间,或者直到没有更多的感染状态(I)的节点。
6. SIS模型
在SIS模型中,恢复的节点立即再次变得易感。
病毒 “strength”: s= β/ δ
一个图的产生流行病的阈值为 τ,如果s= β/ δ<
τ,则流行病不会发生。则:
第七章 图像特征提取
- 图像内容识别:感知 ➡ 预处理 ➡ 特征提取 ➡ 分类
- 特征提取:将原始数据转换为适合计算机处理的格式。包括特征检测和特征描述两部分。
- 特征:待标记或区分的明显属性或描述。
- 种类:
- 应用对象:像素特征、纹理特征、区域特征、关键点特征
- 特征范围:局部特征、全局特征
一、像素特征
- RGB色彩空间
- HSI色彩空间(色调、饱和度、亮度)
- 两者之间的转化
二、纹理特征
2.1 共生矩阵描述子
Q是定义两个像素相对位置的一个算子。
G是一个矩阵(共生矩阵),gij表示图像中zi和zj像素在Q规定的位置上出现的次数。
例如:Q的定义是“右边的一个像素” (即一个像素的相邻像素定义为其右侧的一个像素)
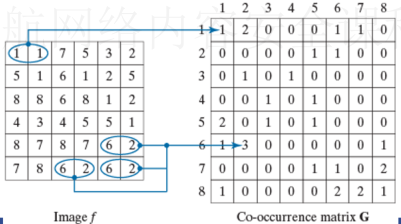
共生矩阵描述子,用于描述共生矩阵的统计特性。从而进一步计算最大概率、相关、对比度、能量、同质、熵等。
2.2 局部二值模式(LBPs)
在一个3*3区域中,将四周八个亮度大于等于中心的记为1,小于的记为0。周围八个01字符按照某顺序排列后得到一个8位的01串,转换为十进制后得到一个用来表示局部纹理模式的数值。
旋转不变性:对01串不断进行循环右移,得到值最小的一个。
在利用像素LBP来表达区域特征的应用中的应用中,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
三、区域特征
3.1 梯度方向直方图-HOG
算法步骤:
确定窗体、块的大小和形状
全局光度归一化
为了减少光照影响,处理光线太暗或太强的情况,需要将整个图像进行归一化处理:灰度化和Gamma校正。在图像的纹理强度中,局部的表层曝光贡献的比重较大,这种处理能够有效地降低图像局部的阴影和光照变化。
计算方向直方图
在每个像素处,梯度有一个大小和一个方向。x方向梯度图会强化垂直边缘特征,y方向梯度图会强化水平边缘特征。这就使得有用的特征(轮廓)得到保留,无关不重要的信息被去除。
构建方向直方图
把整个图像划分为若干个8x8的小单元,称为cell,并计算每个cell的梯度直方图。
将角度范围分成9份,也就是9 bins,每20°为一个单元,也就是这些像素可以根据角度分为9组。将每一份中所有像素对应的梯度值进行累加,可以得到9个数值。直方图就是由这9个数值组成的数组,对应于角度0、20、40、60... 160。
将这 8x8 的cell中所有像素的梯度值加到各自角度对应的bin中,就形成了长度为9的直方图。
对比度归一化
为了处理不同位置上由于光照变化引起的梯度强度不同和前景背景对比度不同局部对比度必须归一化。即使每个块(block,是2*2个cell)之间有重叠,每个块 (重叠的) 也是独立地进行归一化。
形成HOG描述子
每个胞体进行归一化作为分量组成块。然后把窗口内所有块 (重叠) 组合起来形成最后的描述子。 HOG描述子是用来描述整体窗口的。
四、关键点特征
4.1 Harris角点特征
使用一个滑动窗口在图中滑动,可以得出以下结论:
- 一个平坦区域,在各方向移动,窗口内像素值均没有太大变化;
- 一个边缘特征(Edges),如果沿着水平方向移动(梯度方向),像素值会发生跳变;如果沿着边缘移动(平行于边缘) ,像素值不会发生变化;
- 一个角(Corners),不管你把它朝哪个方向移动,像素值都会发生很大变化。
- 两个特征值都较大时,测度R具有较大的正值,这表示存在一个角
- 一个特征值较大一个特征值较小时,测度R具有较大的负值,表示存在边界
- 两个特征值都较小时,表明正在考虑的小块图像是平坦的
4.2 尺度不变特征变换(SIFT)
尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)是一种计算机视觉中常用的特征提取算法,它能够检测图像中的关键点并提取这些关键点的特征描述符,同时具有尺度不变性和旋转不变性。
SIFT算法的主要特点和步骤包括:
- 尺度空间极值检测:SIFT首先在不同尺度下对图像进行高斯模糊处理,然后通过比较每个像素点周围区域的像素值,寻找图像中的局部极值点。这些局部极值点被认为是关键点的候选者。
- 关键点定位:对于检测到的局部极值点,SIFT通过拟合二维高斯函数来确定它们的精确位置,同时估计关键点的尺度(尺度不变性的关键之一)。
- 方向分配:为了增强SIFT特征的旋转不变性,对每个关键点附近的图像区域计算梯度方向直方图,然后选择主要梯度方向作为关键点的主要方向。
- 特征描述符:以关键点为中心,在关键点的周围区域构建一个方向直方图,该直方图描述了关键点周围区域的梯度信息。这个直方图成为SIFT特征描述符,通常包含128个浮点数值。
SIFT特征具有多种优点,包括尺度不变性、旋转不变性、对光照变化的鲁棒性等。因此,SIFT特征常用于图像匹配、物体识别、图像拼接和三维重建等计算机视觉任务中。
五、特征聚合方式
5.1 简单聚合
- 求平均
- 求和
- 求最大值
5.2 特征编码算法
将局部特征聚合为整体的图像特征
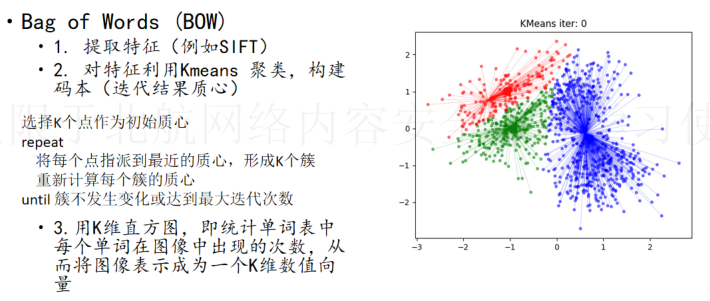
Bag of Words(BOW)
第八章 视频特征提取
视频分类方法:
- 基于手工特征的视频分类
- 深度学习
特征:
- 静态信息:视频帧
- 动态信息:光流
- 长时序特征:轨迹特征(DT、IDT)
1. DT(Dense Trajectories)
"Dense Trajectories" (DT) 算法是一种视频分析方法,主要用于动作识别和相关领域。该算法通过跟踪视频中的特征点来分析运动模式。它在计算机视觉和视频处理领域中得到了广泛的应用,尤其是在运动分析和行为识别等领域。
主要步骤:
- 特征点检测:在视频的每一帧中检测出感兴趣的特征点。这些点通常是图像中的角点或边缘,它们可以代表图像中的显著特征。
- 特征点跟踪:使用光流法(optical flow)跟踪这些特征点随时间的运动。光流是一种估计两个连续视频帧之间特征点运动的技术。
- 轨迹提取:通过连接连续帧中跟踪到的同一特征点的位置,提取出运动轨迹。
- 描述子提取:对提取出的轨迹进行编码,以捕捉运动的特征。这通常涉及到计算轨迹周围的光流统计特征,如方向和速度。
- 分类与识别:使用机器学习或深度学习方法,根据提取的特征对动作进行分类或识别。
优点:
- 详细的运动信息:DT算法通过跟踪视频中的大量特征点来提供详细的运动信息,这对于理解复杂的动作模式非常有用。
- 对小运动敏感:它能够捕捉到微小的运动变化,这在一些需要精细动作识别的应用中非常重要。
- 鲁棒性:DT算法在处理动态背景或摄像机运动时相对鲁棒,因为它依赖于对特征点的局部跟踪。
缺点:
- 计算成本高:跟踪大量特征点需要大量的计算资源,特别是在高分辨率视频中。
- 对遮挡敏感:如果特征点被遮挡,轨迹的连续性会受到影响,从而降低识别精度。
- 视角依赖性:算法的性能可能会受到拍摄角度的限制,特别是在特征点不易区分或在不同视角下表现不同的情况下。
2. IDT(improved dense trajectory)
Improved Dense Trajectories(IDT)是 Dense Trajectories(DT)算法的一个改进版本,专门针对DT算法的一些限制进行了优化。IDT在视频分析和动作识别方面取得了显著的性能提升。以下是IDT相对于DT的主要区别和改进:
摄像机运动补偿
DT:在传统的DT算法中,摄像机的运动可能会对特征点的跟踪产生干扰,导致误判。
IDT:引入了摄像机运动补偿机制。通过估计全局摄像机运动并从特征点轨迹中去除这些影响,IDT能够更准确地捕捉真实的物体或人物动作。
改进的特征描述符
DT:使用标准的描述符,如HOG(Histogram of Oriented Gradients)、HOF(Histogram of Optical Flow)等。
IDT:在这些标准描述符的基础上,加入了MBH(Motion Boundary Histogram)描述符。MBH通过计算光流梯度的直方图来描述边缘运动信息,从而更有效地捕捉动作特征。
过滤静态特征点
DT:跟踪视频中的所有特征点,包括静态和动态的。
IDT:通过忽略静态特征点来减少不必要的计算和噪音。这种方法使得算法专注于更有信息量的动态部分。
轨迹抽样策略
DT:可能在一些区域产生过密的特征点跟踪,导致计算效率降低。
IDT:采用了更有效的特征点抽样方法,确保轨迹在空间上均匀分布,提高了计算效率。
提高了鲁棒性
DT:在处理复杂场景时可能会受到背景杂乱等因素的干扰。
IDT:通过上述改进,提高了对复杂背景和摄像机运动的鲁棒性,能够在更多样化的环境中准确地进行动作识别。